This note explains the overall moves to make when you are writing an application on top of the W3C Sample Code Library (libwww). For details on how to use the library, you should look at the User's Guide.
It is a good idea to have
a look at our example applications:
This quick guide takes you through the basic steps necessary to create your own application with all the power of the W3C Sample Code Library:
The HTInit module is a special module in that it defines the capabilities of the Library. Think of libwww as a core that can do absolutely nothing on its own. All the functionality comes from modules that are registered dynamically at runtime. This is why it is so important to use the initialization function mentioned above. The library basically boot-straps itself to find out what it is capable of doing.
When you unpack the library you already have a lot of functionality to plug in. You have protocol modules that can access HTTP, FTP, Gopher, WAIS, NNTP, Telnet, TN3270, rlogin, services and the local file system. You also have stream converters that handles HTML documents, plain text documents, MIME documents and various conversions between these data formats. Furthermore you have the possibility of defining presenters that use external viewers to present for example images, audio files etc.
By default, the HTInit module contains functions to enable all the functionality that the library provides, but you might want to change this, for example if you have a special image viewer that you would like to use. The way to do this is either to modify the HTInit module or to override HTInit with your own version. It's described in more detail in the User's Guide what it means to override a Library module.
Both converters and presenters are stored in a linked list (the HTList object). This list can either be bound to a global list of converters and presenters that are used in all requests or you can bind the lists locally to a single request object in which case it is only used in this particular case.
Converters are streams that are capable of converting directly from one data format to another, for example from a HTML document to some kind of presentation format that the user can actually see on the screen. This is the fastest way of presenting an object to the user as it doesn't require external applications to step in and do the presentation.
extern void HTConverterInit (HTList * conversions);
Presenters are used to present a data format to the user by calling an external program, for example a post script viewer. In practice presenters work by first saving the data object in local file and then spawn off the external viewer. This is the reason why it is a big advantage to use a converter instead as the presentation to the user then can happen as more and more of the data object arrives over the network.
extern void HTPresenterInit (HTList * conversions);
By default the Library enables all available protocol modules but if this
is desired then it can easily be changed using the HTProtocolInit
function. An example is if you want to make an application that only can
speak HTTP, then you can disable the initialization of all the other protocol
modules by simply taking them out of the HTProtocolInit function.
extern void HTProtocolInit (void);
Not all protocols support the notion of describing the data format of a data object. An example if FTP where only two modes are possible: text and binary. However this is not sufficient in order to select an appropriate converter of presenter (both images and audio files are binary data object but can in general not be handled by the same application). This is also a problem when accessing the local file system which in most cases do not keep information about the data format.
The library solves this by looking into a table of bindings between a file suffix and the corresponding data format. By default the Library defines a long list of the "most common file suffixes" but the list is of course configurable! If you look into the HTInit module again, you will find a function called:
extern void HTFileInit (void);
you will find that it is just a question of adding new suffixes that are not mentioned. However, it is not necessary to list all possible suffixes. Luckily the first couple of line in many data objects tell what kind of data they contain and the Library uses this to try and guess unknown data formats.
The library contains code for presenting a data object in a text based application as is the case with the Line Mode Browser, but as this is not generally sufficient GUI clients must overwrite the data object presentation modules in the Library in order to take advantage of a more advanced user-interface. Just to make it more flexible this can be done in three ways depending on how much you want to do yourself. The three interfaces are illustrated below:
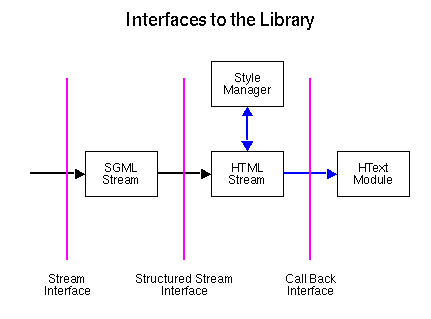
You are free to define the structure of the hypertext object (the declaration can be found in the HText module. You may want to define your own styles and font definitions.
The library handles a persistent file cache which provides intermediate term storage of cacheable objects. However the Library also has a notion of a memory cache but this is not maintained by the Library itself but by the application. The reason for this is that the Library does not know what kind of data format the the application is capable of storing or where they are stored, and it also allows the application to control the memory management, that is how much space to use for storing data objects in memory.
If the application wants a memory cache (which has an important performance impact) it must register a memory cache handler that can make a decision whether a data object is in memory or not and if it is stale or not. Every URL has an associated HTAnchor object that stores all known information about that URL, for example the title, length of the data object (if any) etc. The Library calls the memory handler on every request but before making a decision about a data object, the memory cache manager can consult the requested anchor object to find out if it has expired etc. A memory handler is registered and unregistered using the functions
typedef int HTMemoryCacheHandler (HTRequest * request, HTExpiresMode mode, char * message); extern BOOL HTMemoryCache_register (HTMemoryCacheHandler * cbf); extern BOOL HTMemoryCache_unRegister (void);
The handler can use two return codes which both are defined in the HTUtils modules.
HT_LOADED
HT_ERROR
An example of a memory handler can be found in the Line Mode Browser in the GridText module. You can also see where it is registered as the memory handler in the Library in the HTBrowse.c module
The Library has a very flexible event model that allows an application to either use it's own event loop that the library can makes calls to or to use the event loop in the HTEvent module in the library. In most cases the library event loop is sufficient which is the case for example on Mac, Window, and Unix platforms.
The application can register as many event handlers for as many channels that it can get input on. In the case of the Line Mode Browser, input can only be sent via standard input, so only one event handler is necessary. However if more than one channel is available then they can all be associated with an event handler by registering them in the Library. An event handler is a function of the type
typedef int HTEventCallBack (SOCKET sockfd, HTRequest * request, SockOps ops);
and they can be registered in two ways depending on the event channel:
In the first case use the following functions to register and unregister a handler:
extern int HTEvent_Register (SOCKET sockfd, HTRequest * request, SockOps ops, HTEventCallBack *cbf, HTPriority priority); extern int HTEvent_UnRegister (SOCKET sockfd, SockOps ops);
See the HTEvent module for more information on the arguments. Likewise if you are on for example a Windows NT platform then use the following functions:
extern int HTEvent_RegisterTTY (SOCKET sockfd, HTRequest * request, SockOps ops, HTEventCallBack *cbf, HTPriority priority); extern int HTEvent_UnRegisterTTY(SOCKET sockfd, SockOps ops);
The return code from an event handler is simple but very important. There are two allowed values:
It helps understanding event handlers if you think of the Library as a coke machine (the ones with a coin slot only - the ones which also has a bill slot work differently!) Event handlers are the coin slot on top where you can request a service from the library. You are guaranteed that the machine never returns any coins to you the same way - they always come out at the bottom of the machine. This means that the Library always returns "Thanks, I have received your request - please look for the response at the bottom" on any request started from within an event handler. In the library case the result is always returned in the request termination handler that is the "bottom" of the Library machine.
The application can register a callback function that is called whenever a request has terminated, regardless. The callback function can furthermore be registered to be called regardless of the status code or on upon a specific codes. The set of status codes is:
HT_LOADED
HT_INTERRUPTED
HT_ERROR
HT_NO_DATA
HT_RETRY
extern time_t HTRequest_retryTime (HTRequest * request);
Return codes are not used from termination handlers.
If you have additional headers that you want to experiment with you can register a header parser to handle all unknown headers. This handler is called whenever an unknown header is encountered when parsing the object header. If the returns YES then the MIME parser stores the metainformation in the anchor object if self so that it can be found at a later point in time. If the handler returns NO, then the header is discarded.
The header passed to the call back function will be in normal NULL terminated C string without any CRLF. The line will also be unwrapped so that it is easier to parse for the call back function.
typedef int HTMIMEHandler (HTRequest * request, char * header); extern int HTMIME_register (HTMIMEHandler * cbf); extern int HTMIME_unRegister (void);
You can register a call back function together with a timeout that is used in the select call of the event loop. When the select() call times out, the call back function is called. The registration can either be so that the call back always is called when that the select call times out or only when Library sockets are in use.
typedef int HTEventTimeout (HTRequest *); extern BOOL HTEvent_registerTimeout (struct timeval *tp, HTRequest * request, HTEventTimeout *tcbf, BOOL always);
The Access module has a set of functions that works as a user interface to the request manager. You can call the request manager directly but often it is simpler to use the Access module. As mentioned, the request manager returns immediately and the result of the request is handled back to the application using the termination handlers.
The Library's represents internally location strings as URLs which means that they always are escaped. Only when it is required to access a resource are they unescaped, for example via FTP. All location strings passed to the Library are also treated as URLs which means that they must be escaped already. Hence in the case of the request methods mentioned aboce, all URL arguments must be escaped if the resource is to be found.
Most often this is only a problem when people type in location strings directly, for example using "goto location" etc. In the Escape module the Library provides two functions for escaping location strings into URLs and unescaping URLs into location strings:
typedef enum _HTURIEncoding {
URL_XALPHAS = 0x1,
URL_XPALPHAS = 0x2,
URL_PATH = 0x4
} HTURIEncoding;
extern char * HTEscape (const char * str, HTURIEncoding mask);
extern char * HTUnEscape (char * str);
Multiple simultaneous requests can be started at any time from within an event handler. It is simply a question of calling one of the load functions in the Access module. The Library keeps a request queue where all active requests are kept. The application can define the maximum number of open sockets that can be open at any one time. This number is by default 6 but can be changed using the following functions:
extern BOOL HTNet_setMaxSocket (int newmax); extern int HTNet_maxSocket (void);
If there are no free sockets available the request is put into a pending queue and started as soon as possible.
When multiple requests can be initiated simultaneously it is in general not possible to predict the order that the results return to the application. This is a function of the size of the individual data objects, net work speed etc. In order to keep track of ordering of the requests, for example in the history list, it is necessary to put them into some kind of context. The Library provides the hooks for maintaining a context together with the Request object by the following methods:
typedef int HTRequestCallback (HTRequest * request, void *param); extern void HTRequest_setCallback (HTRequest *request, HTRequestCallback *cb); extern HTRequestCallback *HTRequest_callback (HTRequest *request);
The callback function can be passed an arbitrary pointer (the void part) which can describe the context of the current request structure. If such context information is desired then it can be set using the following methods:
extern void HTRequest_setContext (HTRequest *request, void *context); extern void *HTRequest_context (HTRequest *request);
There is no limit to the definition of a context data object and the memory management if entirely up to the application. The Request object simply carries the information around.
Any request can be interrupted from an event handler by calling either of the functions (the first kills a specific request, the second is more radical and kills them all):
extern BOOL HTRequest_kill (HTRequest * request); extern BOOL HTNet_killAll (void);
The library has a set of modules that are not called from within the library at all but can be used by the application. Two examples are a History manager and a Log manager that provides functionality for keeping a history list of visited objects and to provide logging of the results. The application is free to use there modules but does not have to.
The library has a basic User Messages and Prompts module which is intended for the Line Mode Browser. In case you are building a GUI client you would probably want to write your own version using windows etc. This can be done by overriding the module in the Library with your own that has the same set of functions as described in the User's Guide.
This is a short set of recommendation on when to free objects in memory.
@(#) $Id: Using.html,v 1.23 2000/08/04 08:46:18 kahan Exp $