1 Introduction
Anticipating the increase in online video and audio in the upcoming years, we can foresee that it will become progressively more difficult for viewers to find the content using current search tools. In addition, video services on the web that allows for upload of video, needs to display selected information about the media documents which could be facilitated by a uniform access to selected metadata across a variety of file formats.
Unlike hypertext documents, it is more complex and sometimes impossible to deduce meta information about a medium, such as its title, author, or creation date from its content. There has been a proliferation of media metadata formats for the document's authors to express this metadata information. For example, an image could potentially contain [EXIF], [IPTC] and [XMP] information. There are also several metadata solutions for media related content, including [MPEG-7], Yahoo! [MEDIA RSS], Google [Videositemaps], [VODCSV], [TVAnytime] and [EBU P/Meta]. Many of these formats have been extensively discussed in the deliverables [XGR Vocabularies] and [XGR Image Annotation] of the W3C Multimedia Semantics Incubator Group , which provide a major input to this Working Group.
The "Ontology for Media Object 1.0" will address the intercompatiblity problem by providing a common set of heterogeneousproperties to define the basic metadata needed for multimedia objects byand the semantic links between providing a common set of properties. It will also help circumventing the current proliferation of video metadata formats by providing full or partial translation and mapping between the existing formats. The ontology will be accompanied by an API that provides uniform access to all elements defined by the ontology, which are selected elements from different formats.
The main scope of this document are videos. Metadata for other media objects like audio or images will be taken into account if it is applicable for videos as well.
This document specifies the use cases and requirements that are motivating the development of the "Ontology for Media Object 1.0". The scope is mainly video media objects, but we take also other media objects into account if the metadata information can also be
applied to video,related but not only to video, e.g. the creation date. video.
The development of the requirements has three major inputs: Use cases, analysis of existing standards, and a description of canonical media processes.
2 Purpose of this draft publication
This initial version of this document contains only a small set of use cases and requirements. Nevertheless it is being published to gather wide feedback on the general direction of the Working Group. Hence, we would like to encourage especially feedback on 6 Requirements, the requirements which we are planning to implement, or others which we are planning not to take into account.
Currently, there is an additional section under development, describing a top-down modeling approach to describe the media annotation problem. The Working Group is considering to publish that section in an updated version of this document.
3 Purpose of the Ontology and the API
The following figure visualizes the purpose of the ontology of the API and their relation to applications.
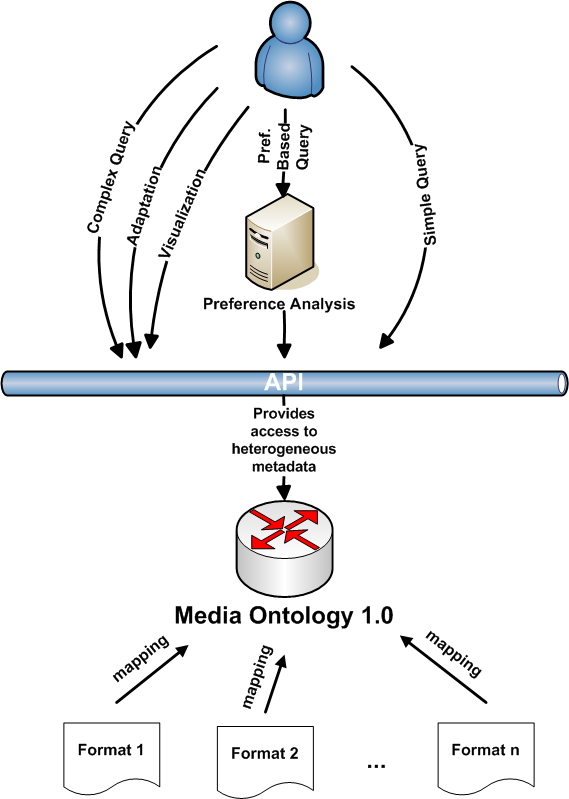
The ontology will define mappings from properties in formats to a common set of properties. The API then will define methods to access heterogeneous metadata, using such mappings. An example: the property createDate from XMP [XMP] can be mapped to the property DateCreated from IPTC [IPTC]. The API will then define a method getCreateDate that will return values both from XMP and IPTC metadata.
An important aspect of the above figure is that everything visualized above the API is left to applications, like: languages for simple or complex queries, analysis of user preferences (like "preferring movies with actor X and suitable for children"), or other mechanisms for accessing metadata. The ontology and the API provide merely a basic, simple means of interoperability for such applications.
5 Use Cases
5.1 Mobile
| Editorial note | |
| To be revised. We want to take into account the following aspects: Context aware services (use of geo location information), media adaption due to device capabilities, metadata types. |
5.2 Interoperability between Media resources acrossa Cultural Heritage Institutions
| Editorial note | |
| To be checked |
Summary: Accessing media collections of different cultural heritage institutions (libraries, museums, archives, etc.) on the Web.
Related requirements:
Description / Example:
The collections of cultural heritage institutions (libraries, museums, archives, etc.) are increasingly digitised and made available on the Web. These collections range from text to image, video and audio (music and radio collections, for example). Acollections comprehensive, professionally created documentation is usually available, however, often using domain specific or even proprietary metadata models. This hinders accessing and linking these collectionscollections. The media types that are archived in ana cultural heritage perspective range from image to homogeneous or centralized way and linking them across collections.
For example, Jane is a TV journalist searching for material about some event in contemporary history. She is interested in televisionmovie clips and radio broadcasts from this event, along with photos and newspaper articles. All these resources come from different collections,languages. She and some are in different languages. A homogeneous way of accessing them across the Web would improve her work. Web.
5.3 Recommendation across different media types
Summary: Accessing heterogeneous media objects metadata as the input to the creation of recommendations which is based on user preferences.
Related requirements:
Description / Example:
People nowadays are able to enjoy large number of programs from different content providers (broadcasting companies, Internet video website, etc.). To achieve better user experience, user history based recommendation is very promising. Recommendation attempt to reduce contents overload and retain users by selecting a subset of contents from a universal set based on user preferences. However, different content providers usually have their specific or proprietary metadata models, which is one of the key problems faced by recommendation service providers. Ontology across different metadata sets can allow recommendation systems to give larger selected contents to users than separated metadata.
Company A is an IPTV add-value service provider. One of their service is to recommend users potentially like programs based on watching history or explicit rating on programs. In their system, users are able to watch regular TV programs with electronic program guide (EPG) format metadata, YouTube like videos with website specific metadata model, etc. To recommend programs uniformly without a common set of vocabularies, they need to design own integrated media annotation model.
5.4 Life Log
Use case summary: combining heterogeneous metadata from life logs, to allow searching personal life log information, potentially enriched with geolocation information.
Related requirements:
Description / Example:
A person captures his experience as well as their entire lives by creating images, audios and videos in the web. They are namely a life logs today. Those life logs are made by various information such as time, location, creator's profile, human relations, and even emotion. In case the life logs are accessibly by means of the ontology, he/she can easily and efficiently search for his/her personal life log information, including emotional information using a vocabulary like [Emotions ML 1.0], or geolocation information on the web, using the [Geolocation API] specification, whenever necessary.
5.5 Access via web client to metadata in heterogeneous formats
Use case summary: Accessing metadata in heterogeneous formats for web developers
Related requirements:
Description / Example:
John is developing a JavaScript library for accessing metadata of media objects (e.g. video) in various formats. His library can be used to make queries of the media objects like:
"Find me all media objects which have been created by a specified person"
"Find me all media objects which have been created this year"
"Find me all videos which are not longer than a specified time"
"Extract all user added tags from all media objects available"
This use case is related to many other use cases. Nevertheless it is mentioned separately since, different to other requirements, its implementation requires only a small set of requirements. Also, the purpose of this use case is not to require or to propose developing a query language on its own. However, the ontology can be used as an input for the development of such a language.
5.6 User generated Metadata
Use case summary: Adding or linking to external metadata by different users.
Related requirements:
Description / Example:
John wants to publish comments on the last movies he has seen on http://example.cheap-vod.com/ . For each movie, he uses the description metadata field to provide a personal summary of the movie (with incentive to see or avoid the movie according to his own opinions), and the ranking metadata. John is also not satisfied with the genre classification of the website, so he uses the genre metadata field to provide his appreciation of the genre with regard to a better scheme. He then publishes these metadata on his blog (may be in the form of a podcast), but only links to the videos themselves.
Jane, a friend of John's and another cheap-vod customer, can now configure her cheap-vod account or her browser, to have John's metadata added to or replacing the original metadata embedded in each file.
Now Jane wants to study more particularly the characters of the movie. For making this easier, she defines one custom metadata field for each of the main characters, and sets these fields to "yes" or "no" for each sequence, to indicate if they contain that character or not. See the following example, represented as RDF/Turtle [Turtle]:example:
<http://example.library.myschool.edu/rose.ogv#some_fragment_identifier>
dc:title "Meeting Tom Baxter" ;
dc:description "Cecilia sees the movie several times when...." ;
custom:cecilia "yes" ;
custom:tom "yes" ;
custom:gil "no" ;
custom:monk "no".
5.7 Use cases: to be done
| Editorial note | |
| In a future draft of this document, the following use cases will be spelled out separately, integrated into existing use cases or dropped. |
6 Requirements
This sections describes requirements for the ontology and the API. The Working Group has agreed to implement the following requirements. For the other requirements, there is no agreement yet, and the Working Group is asking reviewers of this document for feedback about their implementation.
The requirements which the Working Group currently does not have agreement to take into account are the following:
6.1 Requirement r01: Providing methods for getting structured or unstructured metadata out of media objects in different formats
Description: The API MUST provide methods for getting metadata out of media objects in different formats.
Rationale: This is a core requirements. Its implementation is necessary for nearly all use cases.
Target (API and / or ontology): API
6.2 Requirement r02: Providing methods for setting metadata in media objects in different formats
Description: The API MUST provide methods for setting metadata in media objects in different formats.
Rationale: The implementation of this requirement is mainly necessary for use cases which involve change of media objects by users.
Target (API and / or ontology): API
Note:
The implementation of this requirement may impose several problems, like: how to set information in formats which have more detailed information than our ontology, or how to implement the setting process in the API (e.g. what protocol to use). Due to such problems and since there seem to be no implementations achieving this functionality, we might not take this requirement into account.
6.3 Requirement r03: Providing in the API a means for supporting structured annotations
Description: The API MUST provide a means to support structured metadata to media objects, like the name of the creator being structured in "first name" and "last name".
Rationale: There are existing, widely used formats like [XMP] which are defined in a structured manner. To be able to support meta information for media objects, including such formats, the API needs to have a means to achieve this.
Target (API and / or ontology): API
6.4 Requirement r04: Providing a means to access custom metadata
Description: It MUST be possible to access custom metadata to media objects. "custom metadata" means metadata that is not defined in a standardized format, but which is being created entirely by the user.
Rationale: The ability to access custom metadata is necessary for the use case user generated metadata.
Target (API and / or ontology): API which needs to provide a method to add custom metadata, and the ontology which needs to provide an extensibility mechanism.
6.5 Requirement r05: Providing the ontology as a simple set of properties
Description: the ontology MUST be available as a simple set of properties, to hide complexity for whose who do not need it.
Rationale: In use cases like access via web client to metadata in heterogeneous formats it is important to hide the potentially complex ontology from the web developer. This will foster ease of use and wide spread adoption.
Target (API and / or ontology): API and ontology
6.6 Requirement r06: Specifying an internal or external format for the ontology
Description: The ontology MUST be provided not only in prose description but also as an internal or external format.
Rationale: to be able foster interoperability between applications, a common format for the ontology will be helpful. To avoid the need to process this format for all implementations, the specification(s) will provide separate slices of conformance, see Requirement r11: providing the ontology in slices of conformance.
Target (API and / or ontology): Mainly the ontology, but possibly also the API, if we require it to process this format.
6.7 Requirement r07: Introducing several abstraction levels in the ontology
Description: The ontology MUST provide several abstraction levels.
Rationale: Several metadata standards like [FRBR] or [CIDOC] allow referring to multimedia objects on several abstraction levels, in order to separate e.g. a movie, a DVD which contains the movie and a specific copy of the DVD. Especially for collections of multimedia objects, knowledge about such abstraction levels is helpful, as a means for accessing the objects on each level.
Target (API and / or ontology): ontology and potentially API, if we want to provide access to metadata and multimedia objects on several abstraction levels.
6.8 Requirement r08: Being able to apply the ontology / API for collections of metadata
Description: It MUST be possible to access collections of metadata.
Rationale: For processing collections of multimedia objects, access to collections of metadata referring potentially to more than one object is necessary. As an example for the need for this requirement and a related requirement see Requirement r07: Introducing several abstraction levels in the ontology.
Target (API and / or ontology): API and ontology
6.9 Requirement r09: Taking different roles in metadata processing into account
Description: Different roles in metadata processing MUST be taken into account.
Rationale: Metadata is being dealt with by for example producers of metadata (e.g. a video camera), changers (e.g. a person which modifies initially created metadata) and consumers (e.g. an application which processes metadata to make it accessible for search). If several pieces of metadata, created by machines or people in different roles, are in conflict (e.g. contradictory creation dates), a description of provenance related to roles can be useful for conflict resolution (e.g. "metadata produced by the changer has provenance over metadata produced by the creator").
Target (API and / or ontology): ontology
6.10 Requirement r10: Being able to describe fragments of media objects
Description: It MUST be possible to relate metadata to fragments of media objects.
Rationale: Processes like search may be specific to fragments of media objects, e.g. a search for all kiss scenes in a movie. The implementation of this requirement provides the means to implement such processes.
Target (API and / or ontology): none of these
6.11 Requirement r11: Providing the ontology in slices of conformance
Description: The ontology MUST be provided in a prose description and MAY be provided in different serializations (RDF, XML). The yet to be produced general conformance description MUST require implementations to take the prose description into account. Additional conformance descriptions, being specific to a serialization, MAY be provided.
Rationale: Existing metadata formats use a wide range of serializations like RDF and XML. To foster a widespread adoption of the ontology, we do not want to be specific to one serialization, but rather state that following the prose description is sufficient for an implementation. If there is a interest in the Working Group to create one or more serializations, we may provide additional types of conformance for them.
Target (API and / or ontology): ontology
6.12 Requirement r12: Provide support for controlled vocabularies for the values of different properties
Description: It MUST be possible to take information from controlled vocabularies for certain properties into account.
Rationale: Media archives often make use of controlled vocabularies (e.g. classifications, thesauri, ontologies) for certain properties. Providing access to knowledge about which vocabulary is actually being in use for a media object, is an important requirement for such archives.
Target (API and / or ontology): ontology (for describing properties which need a slot for specifying a controlled vocabulary) and the API ( for getting information about which vocabulary is being used for a media object)
6.13 Requirement r13: Allow for different return types for the same property
Description: It MUST be possible to provide different return types for the same property.
Rationale: Some properties are defined with the same name and functionality (e.g. conveying information about the creator of a media object), but use different value types (e.g. string versus URI). This raises the question whether the API should be specific to only one return type, or allow for several ones.
Target: API