What does this title means ? Simply that there is currently a huge amount of precompiled software freely available for Linux, but it's hard to find the one one need:
I suggest here a mechanism to help finding the packages needed. It is based on the propagation of Metadata (structured, machine readable informations) about the available binary packages. It is based on the lessons learned by building the RPM database on rpmfind.net, the rpm2html program development, the work done on Metadata at W3C, and discussions with Jim Pick (Debian) and Marc Ewing (RedHat).
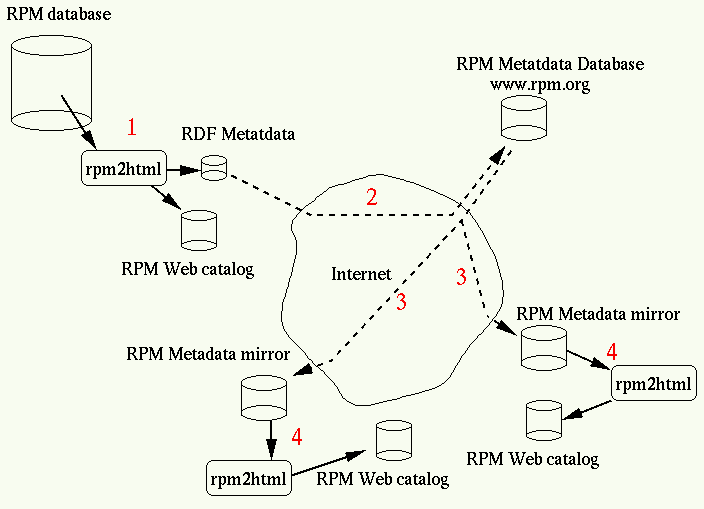
The picture above illustrate the four steps needed: to create, centralize, propagate and expose packages metadata
Basically the idea is to extract useful information about a package, like application name, revision, author, dependancies, etc., and save them in a format that is predefined and can be automatically parsed to extract the informations. This is precisely Metadata (data about data) and I suggest to use the RDF Metadata encoding - based on XML - the metadata encoding proposed by W3C. Ideally the description for the metadata should be independant of the package format, however in practice it may be, for example the package dependancies are more sophisticated in Debian packages than in RPM ones. Here is for example an RDF file describing the RPM package "rpm2html-0.90-1.i386.rpm" :
<?XML version="1.0">
<?namespace href ="http://www.imag.fr/TR/WD-rdf-syntax#/" AS = "RDF"?>
<?namespace href ="http://www.rpm.org/" AS = "RPM"?>
<RDF:RDF>
<RDF:Description RDF:HREF="ftp://ftp.redhat.com/pub/contrib/i386/rpm2html-0.90-1.i386.rpm">
<RPM:Name>rpm2html</RPM:Name>
<RPM:Version>0.90</RPM:Version>
<RPM:Release>1</RPM:Release>
<RPM:Distribution>Unknown</RPM:Distribution>
<RPM:Vendor>Daniel Veillard</RPM:Vendor>
<RPM:Size>13244</RPM:Size>
<RPM:URL>http://rpmfind.net/linux/rpm2html/</RPM:URL>
<RPM:BuildDate>Sun Mar 29 19:44:53 EST 1998</RPM:BuildDate>
<RPM:BuildHost>rpmfind.net</RPM:BuildHost>
<RPM:Group>X11/Applications</RPM:Group>
<RPM:Packager>Daniel Veillard</RPM:Packager>
<RPM:Summary>Translates rpm database into html info</RPM:Summary>
<RPM:Sources>ftp://ftp.redhat.com/pub/contrib/SRPM/rpm2html-0.90-1.src.rpm</RPM:Sources>
<RPM:Description>
</RPM:Description>
Rpm2html tries to solve 2 big problems one faces when
grabbing a RPM package from a mirror on the net and trying to
install it:
- it gives more information than just the filename before
installing the package.
- it tries to solve the dependency problem by analyzing all
the Provides and Requires of the set of RPMs. It shows the
cross references by way of hypertext links.
<RPM:Provides>
<RDF:Bag>
<RPM:Resource>rpm2html</RPM:Resource>
</RDF:Bag>
</RPM:Provides>
<RPM:Requires>
<RDF:Bag>
<RPM:Resource>libz.so.1</RPM:Resource>
<RPM:Resource>libdb.so.2</RPM:Resource>
<RPM:Resource>libc.so.6</RPM:Resource>
<RPM:Resource>ld-linux.so.2</RPM:Resource>
</RDF:Bag>
</RPM:Requires>
<RPM:Files>
/etc/rpm2html.config
/usr/bin
/usr/bin/rpm2html
/usr/doc/rpm2html-0.85
/usr/doc/rpm2html-0.85/CHANGES
/usr/doc/rpm2html-0.85/Copyright
/usr/doc/rpm2html-0.85/PRINCIPLES
/usr/doc/rpm2html-0.85/README
/usr/doc/rpm2html-0.85/TODO
/usr/doc/rpm2html-0.85/config.small
/usr/man/man1/rpm2html.1
/usr/share/rpm2html/msg.de
/usr/share/rpm2html/msg.es
/usr/share/rpm2html/msg.fr
</RPM:Files>
</RDF:Description>
</RDF:RDF>
While this description is definitely not suitable for an human, it can be parsed easily (basic RDF support is already present in Mozilla for example) and numerous tools can take advantage of the medata to process the associated data.
As discussed and demonstrated quickly, these metadata can be easilly generated from the packages themselve (has been done for both RPM and Debian packages), and are usually quite smaller than the binary package themselves.
Since one cannot assume that one entity can actually generate the metadata for all the available Linux binary packages available, some sort of distributed work is needed, for example each maintainer of a Linux distribution or of a set of packages can extract the metadata and make them available along with the packages.
The next step is to centralize these Metadata to build a database as complete as possible, it can be done by mirroring the metadata provided by various maintainers. The key point is that for each package the metadata has to be generated once and uploaded once to the repository.
Why centralizing ? Simply because metadata alone are not very useful, but the cross references one can obtain by gathering and following multiple references are usually far more useful.
Moreover the bigger the database, the higher the probablility to answer a request based on the associated data. Centralizing also ease the spreading of data a lot !
Once the Matadata have been gathered in a unique place, setting up a mirroring scheme is esay and can be done in a very efficient way to propagate the data near the final user, that's the basic mechanism set up for FTP mirrors, it's well known and quite effective. The goal is to offer services based on these Metadata and install them as close as possible from the final user.
Once the Metadata are available a large amount of tools can be build to expose and use their content. A basic idea is to build directories available for searching and locating binary packages, for example rpm2html tool is being modified to support RDF Metadata as input instead of the binary packages. This allow the databases maintainer to point to a near mirror of the binary packages. A lot of other tools can be build using the metadata, like automatic checking of packages, smart installers following the metadata informations to retrieve and install the latest packages and the correct dependancies, easier management of clusters, etc.
$Id: mirroring.html,v 1.6 2001/02/21 18:45:34 veillard Exp $