1. Introduction
1.1. What is ruby?
This subsection is not normative.
Ruby is the commonly-used name for a run of text that appears alongside another run of text (referred to as the “base”) and serves as an annotation or a pronunciation guide associated with that run of text.
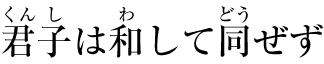
The following figures show two examples of Ruby, a simple case and one with more complicated structure.

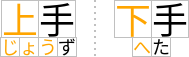
Example of ruby used in Japanese (simple case)
In Japanese typography, this case is sometimes called taigo ruby (Japanese: 対語ルビ, i.e. per-word ruby) or group-ruby, because the annotation as a whole is associated with multi-character word (as a whole).

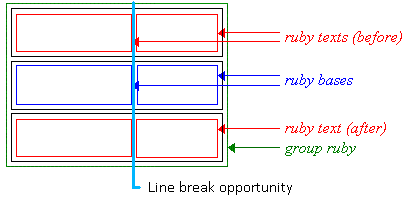
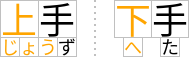
Complex ruby with annotation text over and under the base characters
Notice that to reflect the correct association of hiragana characters and their corresponding Kanji base characters, the spacing within the base-level text is adjusted. (This happens around the fourth Kanji character in the figure above, which has a three-character phonetic gloss.) To avoid variable spacing of the base text in the example above, the hiragana annotations can be styled as a merged annotation, which will look more like the group-ruby example earlier. However because the base-annotation pairings are recorded in the ruby structure, if the text breaks across lines, the annotation characters will stay correctly paired with their respective base characters.
In HTML, ruby structure and markup to represent it is described in the Ruby Markup Extension specification. This module describes the CSS rendering model and formatting controls relevant to ruby layout of such markup.
A more in-depth introduction to Ruby and its formatting can be found in the “What is Ruby“ article [QA-RUBY]. Extensive information about the main ways ruby has traditionally been formatted in Japanese can be found in JIS X-4051 [JIS4051] (in Japanese) and in “Ruby and Emphasis Dots” in Requirements for Japanese Text Layout [JLREQ] (in English and Japanese); Rules for Simple Placement of Japanese Ruby [SIMPLE-RUBY] also describes (in English) one possible approach for Japanese ruby formatting. “Interlinear annotations” in Requirements for Chinese Text Layout [CLREQ] describes the related practices for Chinese typography (in Chinese and English).
1.2. Module interactions
This module extends the inline box model of CSS Level 2 [CSS2] to support ruby.
None of the properties in this module apply to the ::first-line or ::first-letter pseudo-elements; however ruby-position can inherit through ::first-line to affect ruby annotations on the first line.
1.3. Value Definitions
This specification follows the CSS property definition conventions from [CSS2] using the value definition syntax from [CSS-VALUES-3]. Value types not defined in this specification are defined in CSS Values & Units [CSS-VALUES-3]. Combination with other CSS modules may expand the definitions of these value types.
In addition to the property-specific values listed in their definitions, all properties defined in this specification also accept the CSS-wide keywords keywords as their property value. For readability they have not been repeated explicitly.
1.4. Diagram conventions
This subsection is not normative.
Many typographical conventions in East Asian typography depend on whether the character rendered is wide (CJK) or narrow (non-CJK). There are a number of illustrations in this document for which the following legend is used:

- Wide-cell glyph (e.g. Han) that is the nth character in the text sequence. They are typically sized to 50% when used as annotations.
- Narrow-cell glyph (e.g. Roman) which is the nth glyph in the text sequence.
The orientation which the above symbols assume in the diagrams corresponds to the orientation that the glyphs they represent are intended to assume when rendered by the user agent. Spacing between these characters in the diagrams is incidental, unless intentionally changed to make a point.
2. Ruby Box Model
The CSS ruby model is based on the W3C HTML5 Ruby Markup model and the XHTML Ruby Annotation Recommendation [RUBY]. In this model, a ruby structure consists of one or more ruby base elements representing the base (annotated) text, associated with one or more levels of ruby annotation elements representing the annotations. The structure of ruby is similar to that of a table: there are “rows” (the base text level, each annotation level) and “columns” (each ruby base and its corresponding ruby annotations).
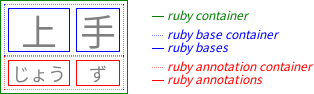
Sets of consecutive bases and their consecutive annotations are grouped together into ruby segments. Within a ruby segment, a ruby annotation may span multiple ruby bases.
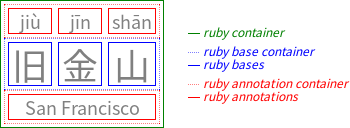
Note: In HTML, a single <ruby> element may contain multiple ruby segments.
(In the XHTML Ruby model, a single <ruby> element can only contain one ruby segment.)
2.1. Ruby-specific display Values
For document languages (such as XML applications) that do not have pre-defined ruby elements, authors must map document language elements to ruby elements; this is done with the display property.
| Name: | display |
|---|---|
| New values: | ruby | ruby-base | ruby-text | ruby-base-container | ruby-text-container |
The following new display values assign ruby layout roles to an arbitrary element:
- ruby
- Specifies that an element generates a ruby container box.
(Corresponds to HTML/XHTML
<ruby>elements.) - ruby-base
- Specifies that an element generates a ruby base box.
(Corresponds to HTML/XHTML
<rb>elements.) - ruby-text
- Specifies that an element generates a ruby annotation box.
(Corresponds to HTML/XHTML
<rt>elements.) - ruby-base-container
- Specifies that an element generates a ruby base container box.
(Corresponds to XHTML
<rbc>elements; generated as an anonymous box in HTML.) - ruby-text-container
- Specifies that an element generates a ruby annotation container box.
(Corresponds to HTML/XHTML
<rtc>elements.)
Authors using a language (such as HTML)
that supports dedicated ruby markup
should use that markup rather than
styling arbitrary elements (like <span>)
with ruby display values.
Using the correct markup ensures that screen readers
and non-CSS renderers can interpret the ruby structures.
Note: Replaced elements with a display value of ruby-base, ruby-text, ruby-base-container, and ruby-text-container are treated as inline-level boxes, as per CSS Display 3 § 2.4 Layout-Internal Display Types: the table-* and ruby-* keywords; replaced elements with a display value of ruby or inline ruby behave according to their outer display type, as per CSS Display 3 § 2.1 Outer Display Roles for Flow Layout: the block, inline, and run-in keywords. (See also § 2.1.2 Non-Inline Ruby.)
2.1.1. The Ruby Formatting Context
Ruby containers are non-atomic inline-level boxes. Like regular inline boxes (see CSS Inline Layout 3 § 2 Inline Layout Model), they break across lines, and their containing block is the nearest block container ancestor. And just as the contents of an inline box participate in the same inline formatting context that contains the inline box itself, a ruby container and its base-level contents participate in the same inline formatting context that contains the ruby container itself.
However ruby containers also establish a ruby formatting context that builds further structure around their segment of the inline formatting context in order to host their annotations. Note: this formatting context is not an independent formatting context. Ruby bases, ruby annotations, ruby base containers, and ruby annotation containers are internal ruby boxes: like internal table elements, they have specific roles in ruby layout, and participate in their ruby container’s ruby formatting context. In addition to their role in the ruby formatting context, ruby bases simultaneously participate in the same base-level inline formatting context as the ruby container, while ruby annotations participate in separate annotation-level inline formatting contexts established by the ruby container.
As with the contents of inline boxes, the containing block for the contents of a ruby container (and all its internal ruby boxes) is the containing block of the ruby container. So floats, for example, are trapped by the ruby container’s containing block, not any of the ruby box types.
2.1.2. Non-Inline Ruby
If an element has an inner display type of ruby and an outer display type other than inline, then it generates two boxes: a principal box of the required outer display type type, and an inline-level ruby container. All properties specified on the element apply to the principal box (and if inheritable, inherit to the ruby container box). This allows styling the element as a block, while correctly maintaining the internal ruby structure.
Note: Absolute positioning or floating an element causes its display value to compute to a block-level equivalent. (See [CSS-DISPLAY-3] or [CSS2] section 9.7.) For the internal ruby display types, this causes their display value to compute to block.
2.2. Anonymous Ruby Box Generation
The CSS model does not require that the document language include elements that correspond to each of these components. Missing parts of the structure are implied through the anonymous box generation rules similar to those used to normalize tables. [CSS2]
- Inlinify block-level boxes: Any in-flow boxes directly contained by a ruby container, ruby base container, ruby annotation container, ruby base box, or ruby annotation box are “inlinified” per [CSS-DISPLAY-3]), and their display value computed accordingly, so that they contain only inline-level content. For example, the display property of an in-flow element with display: block parented by an element with display: ruby-text computes to inline-block.
-
Generate anonymous ruby containers: Any consecutive sequence of
improperly-contained ruby base containers, ruby annotation containers, ruby bases,
and/or ruby annotations (and any intervening white space)
is wrapped in an anonymous ruby container.
For the purpose of this step:
- an improperly-contained ruby base is one not parented by a ruby base container or ruby container
- an improperly-contained ruby annotation is one not parented by a ruby annotation container or ruby container
- an improperly-contained ruby base container or ruby annotation container is one not parented by a ruby container
-
Wrap misparented inline-level content: Any consecutive sequence of text and inline-level boxes
directly parented by a ruby container or ruby base container is wrapped in an anonymous ruby base.
Similarly, any consecutive sequence of text and inline-level boxes
directly parented by a ruby annotation container is wrapped in an anonymous ruby annotation.
(For this purpose, misparented internal table elements are treated as inline-level content since, being parented by ruby boxes,
they will be ultimately wrapped by an inline-level table wrapper box.)
However, if an anonymous box so constructed contains only white space, it is considered intra-ruby white space and is either discarded or preserved as described below.
- Trim leading/trailing white space: Any intra-ruby white space that is not the sole in-flow child of its parent and is the first or last in-flow child of a ruby container, ruby annotation container, or ruby base container is removed, as if it had display: none
-
Remove inter-level white space: Any intra-ruby white space whose immediately adjacent in-flow siblings match one of the patterns below
is inter-level white space and is removed, as if it had display: none.
Previous box Next box any ruby annotation container not ruby annotation ruby annotation -
Interpret intra-level white space: Any intra-ruby white space box
whose immediately adjacent in-flow siblings match one of the patterns below
is assigned the box type and subtype defined in the table below:
The intra-level white space boxes defined above are treated specially for pairing and layout. See below.Previous box Next box Box type Subtype ruby base ruby base ruby base inter-base white space ruby annotation ruby annotation ruby annotation inter-annotation white space ruby annotation or ruby annotation container ruby base or ruby base container ruby base inter-segment white space ruby base or ruby base container ruby base container ruby base container ruby base or ruby base container -
Suppress line breaks: Convert all forced line breaks inside ruby annotations (regardless of white-space value)
as defined for collapsible segment breaks in CSS Text Level 3 § 4.1.2.
The goal of this is to simplify the layout model by suppressing any line breaks within ruby annotations. Alternatively we could try to define some kind of acceptable behavior for them.
- Generate anonymous level containers: Any consecutive sequence of ruby bases and inter-base white space (and not inter-segment white space) not parented by a ruby base container is wrapped in an anonymous ruby base container. Similarly, any consecutive sequence of ruby annotations and inter-annotation white space not parented by a ruby annotation container is wrapped in an anonymous ruby annotation container.
Once all ruby layout structures are properly parented, the UA can start to associate bases with their annotations.
Note: The UA is not required to create any of these anonymous boxes (or the anonymous empty intra-level white space boxes in § 2.3 Annotation Pairing) in its internal structures, as long as pairing and layout behaves as if they existed.
< ruby > ×< rbc > ×< rb ></ rb > ⬕< rb ></ rb > ×</ rbc > ☒< rtc > ×< rt ></ rt > ⬔< rt ></ rt > ×</ rtc > ◼< rbc > ×< rb ></ rb > …</ rtc > ×</ ruby >
where
-
× represents discarded leading/trailing white space
-
☒ represents discarded inter-level white space
-
⬕ represents inter-base white space
-
⬔ represents inter-annotation white space
-
◼ represents inter-segment white space
2.3. Annotation Pairing
Annotation pairing is the process of associating ruby annotations with ruby bases. Each ruby annotation is associated with one or more ruby bases, and is said to span those bases. (A ruby annotation that spans multiple bases is called a spanning annotation.)
A ruby base can be associated with only one ruby annotation per annotation level. However, if there are multiple annotation levels, it can be associated with multiple ruby annotations.
Once pairing is complete, ruby columns are defined, each represented by a single ruby base and one ruby annotation (possibly an empty, anonymous one) from each interlinear annotation level in its ruby segment.
2.3.1. Segment Pairing and Annotation Levels
A ruby structure is divided into ruby segments, each consisting of a single ruby base container followed by one or more ruby annotation containers. Each ruby annotation container in a ruby segment represents one level of annotation for the base text: the first one represents the first level of annotation, the second one represents the second level of annotation, and so on. The ruby base container represents the base level. The ruby base container in each segment is thus paired with each of the ruby annotation containers in that segment.
In order to handle degenerate cases, some empty anonymous containers are assumed:
- If the first child of a ruby container is a ruby annotation container, an anonymous, empty ruby base container is assumed to exist before it.
- Similarly, if the ruby container contains consecutive ruby base containers, anonymous, empty ruby annotation containers are assumed to exist between them.
Inter-segment white space is effectively a ruby segment of its own.
2.3.2. Unit Pairing and Spanning Annotations
Within a ruby segment, each ruby base in the ruby base container is paired with one ruby annotation from each ruby annotation container in its ruby segment.
If a ruby annotation container contains only a single, anonymous ruby annotation, then that ruby annotation is paired with (i.e. spans across) all of the ruby bases in its ruby segment.
Otherwise, each ruby annotation is paired, in document order, with the corresponding ruby base in that segment. If there are not enough ruby annotations in a ruby annotation container, the remaining ruby bases are paired with anonymous empty annotations inserted at the end of the ruby annotation container. If there are not enough ruby bases, any remaining ruby annotations pair with empty, anonymous bases inserted at the end of the ruby base container.
If an implementation supports ruby markup with explicit spanning (e.g. XHTML Complex Ruby Annotations), it must adjust the pairing rules to pair spanning annotations to their bases appropriately.
Intra-level white space does not participate in standard annotation pairing. However, if the immediately-adjacent ruby bases or ruby annotations are paired
- with two ruby bases or annotations that surround corresponding intra-level white space in another level, then the so-corresponding intra-level white space boxes are also paired.
- with a single spanning ruby annotation, then the intra-level white space is also paired to that ruby annotation
- with two ruby bases or annotations with no intervening intra-level white space, then the intra-level white space box pairs with an anonymous empty intra-level white space box assumed to exist between them.
|[ s p a n n i n g a n n o t a t i o n ]| |[ a1 ]|[ws]|[ a2 ]|[ ]|[ a3 ]|[ws]|[ a4 ]| |[ b1 ]|[ws]|[ b2 ]|[ws]|[ b3 ]|[ ]|[ b4 ]|
Blue brackets ([ ]) represent base boxes, red brackets ([ ]) represent annotation boxes, gray bars (|) represent the limits of ruby columns, [ws] represents intra-ruby white space, and [] represents an empty anonymous base or annotation automatically generated to pair with intra-ruby white space in another level. Ruby containers, base containers, and annotation containers are omitted.
2.4. Hiding Annotations: visibility: collapse and auto-hidden ruby
A ruby annotation whose visibility is collapse is a hidden annotation. Additionally, if a ruby annotation has the exact same text content as its base, it is automatically (auto-hidden) by the UA.
a ruby annotation does not affect annotation pairing. However the is not visible, and it has no impact on layout other than to separate adjacent sequences of ruby annotation boxes within its level, as if they belonged to separate segments and the ’s base were not a ruby base but an intervening inline.
振り仮名(ふりがな)
and therefore marked up as
< ruby > < rb > 振</ rb >< rb > り</ rb >< rb > 仮</ rb >< rb > 名</ rb > < rp > (</ rp >< rt > ふ</ rt >< rt > り</ rt >< rt > が</ rt >< rt > な</ rt >< rp > )</ rp > </ ruby >
However, when displayed as ruby, the “り” should be hidden

Hiragana ruby for 振り仮名. Notice there is no hiragana annotation above り, since it is already in hiragana.
< ruby >< rb > 昆< rb > 虫< rb > 記< rt > こん< rt class = easy > ちゅう< rt > き</ ruby >

Although some readers might need pronunciation guidance on all three characters, for other audiences it is more appropriate to hide the annotation on the easier character. Applying visibility: collapse enables this hiding:

The behavior of visibility: collapse differs from visibility: hidden—which makes the annotation invisible, but does not remove its impact on layout:

It also differs from display: none because visibility: collapse preserves pairing relationships, whereas display: none removes the box from the tree entirely, disturbing the pairing of any annotations after it:

When the computed value of ruby-merge on the annotation container is merge, is disabled. When that value is auto, the user agent may decide whether to disable of its annotations, but it is recommended to enable if the user agent’s layout algorithm produces the results similar to separate.
The content comparison for takes place prior to white space collapsing (white-space) and text transformation (text-transform)
and ignores elements (considers only the textContent of the boxes).
Note: Future levels of CSS Ruby may add controls for , but in this level it is always forced.
2.5. White Space Collapsing
As discussed in § 2.2 Anonymous Ruby Box Generation, white space within a ruby structure is discarded:
- at the beginning and end of a ruby container, annotation container, or base container,
- between a base container and its following annotation container,
- between annotation containers.
< ruby > < rb > 東</ rb >< rb > 京</ rb > < rt > とう</ rt >< rt > きょう</ rt > < rtc >< rt > Tō</ rt >< rt > kyō</ rt ></ rtc > </ ruby >
Between ruby segments, between ruby bases, and between ruby annotations, however, white space is not discarded, and is maintained for rendering as inter-base, inter-annotation, or inter-segment white space. (See Interpret intra-level white space, above.)
< ruby > < rb > W</ rb >< rb > W</ rb >< rb > W</ rb > < rt > World</ rt > < rt > Wide</ rt > < rt > Web</ rt > </ ruby >
They also ensure that annotated white space is preserved. For example,
< ruby > < rb > Aerith</ rb >< rb > </ rb >< rb > Gainsborough</ rb > < rt > エアリス</ rt >< rt > ・</ rt >< rt > ゲインズブール</ rt > </ ruby >
Where undiscarded white space is collapsible, it will collapse across adjacent boxes in each line box following the standard white space processing rules [CSS-TEXT-3]. Annotations in separate ruby segments or separated by are not considered adjacent; however all base-level content (including inter-character annotations, which are treated as atomic inlines) is. For collapsible white space between ruby segments (inter-segment white space), the contextual text for determining segment break transformations is thus given by the ruby bases on either side, not necessarily the text on either side of the white space in source document order (which could include interlinear annotations).
< ruby > 屋< rt > おく</ rt > 内< rt > ない</ rt > 禁< rt > きん</ rt > 煙< rt > えん</ rt > </ ruby >
However, white space that does not contain a segment break does not collapse completely away, so this markup will display with a space between the first and second ruby pairs:
< ruby > 屋< rt > おく</ rt > 内< rt > ない</ rt > 禁< rt > きん</ rt > 煙< rt > えん</ rt > </ ruby >
3. Ruby Layout
When a ruby structure is laid out, its base level is initially laid out on the line exactly as if its ruby bases were a regular sequence of inline boxes and the ruby container a regular inline box wrapped around it.
If a ruby container has any inter-character annotations, they are laid out into the base level as detailed in § 3.2 Inter-character Ruby Layout. Subsequently, the base container is sized and interlinear annotations are laid out as detailed in § 3.1 Interlinear Ruby Layout.
As in other CSS layout models, relative positioning, transforms, and other graphical effects apply after this layout of the boxes.
3.1. Interlinear Ruby Layout
Interlinear ruby annotations within a level are initially laid out as if they were inline boxes participating in the same inline formatting context, effectively establishing a line box for that level of annotation in the ruby container. Annotations and bases are aligned to each other by adjusting their spacing as described below.
3.1.1. Inline-axis Interlinear Layout
In the inline axis, interlinear ruby annotations are aligned with respect to their ruby base boxes in accordance with their annotation container’s ruby-merge value.
When ruby-merge is separate, each ruby column is sized to the widest content (ruby base or ruby annotation) in that column. In the case of spanning annotations (whether actually spanning or pretending to span per ruby-merge: merge), if the content of a spanning annotation would be wider than the columns that it spans, then the difference is distributed equally among the spanned columns. If a ruby segment contains multiple spanning annotations, this distribution of additional space is performed starting with the spanning annotations that span the least number of bases, and then in increasing number of bases spanned. Each ruby base and ruby annotation is then sized to exactly span its column(s).
Note: If there are multiple annotations in different levels spanning the same number of bases that overlap but do not coincide, the distribution of space is undefined. Note this is not possible with HTML markup, but can happen in markup languages with explicit spanning such as in [RUBY].
If any ruby annotation in an annotation container with ruby-merge: auto is wider than its base, then ruby annotations in that annotation container may extend outside of their column(s). When they do, their influence on the measure of the columns they intersect is up to the user agent, provided that the ruby segment is made wide enough to fit all its content.
Inter-character annotations are interleaved between columns: they factor into measurement of annotations that span both adjacent columns, but are not included in either column and are never affected by the sizing or positioning of interlinear annotations.
Within each base and annotation box, how the extra space is distributed when its content is narrower than the measure of the box is specified by its ruby-align property.
Blue brackets ([ ]) represent base boxes, red brackets ([ ]) represent annotation boxes, and gray bars (|) represent the limits of ruby columns. Ruby containers, base containers, and annotation containers are omitted.
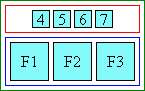
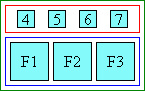
- Separate / non-spanning:
-
|[ a1 ]|[ a2 ]|[annotation-3]| |[base 1]|[base 2]|[ base 3 ]|
Boxes within each column are sized to match the widest box of that column. The value of ruby-align on each base box and annotation box is used to distribute the extra space in each box.
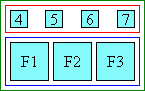
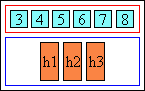
- Spanning (short):
-
|[ a1 ]|[ short span ]| |[base 1]|[base 2]|[base 3]|
When a spanning annotation is shorter than the spanned bases, there is no extra space to distribute to these bases. Extra space within the spanning annotation is distributed according to ruby-align on that annotation box, as for non spanning ones.
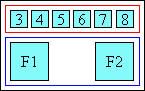
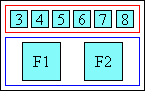
- Spanning (long):
-
|[ a1 ]|[spanning annotation]| |[base 1]|[ base 2 ]|[ base 3 ]|
When the spanning annotation is longer than the spanned base boxes, the extra space is distributed equally between them.
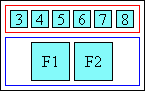
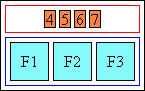
- Merged (short):
-
|[merged annotation]| |[base 1]|[base 2]|[base 3]|
A merged annotation behaves similarly to a spanning one, except that distribution of any extra space in it is determined by the value of ruby-align on the annotation container, not on any of its annotation boxes.
- Several levels, with spanning annotation:
-
|[ a1 ]|[ annotation-2 ]|[ a3 ]| |[long annotation spanning all content]| |[ base 1 ]|[ base 2 ]|[ base 3 ]|
|[ xx ]|[annotation spanning bases]| |[ a1 ]|[ annotation-2 ]|[ a3 ]| |[base 1]|[ base 2 ]|[ base 3 ]|
In these two examples with multiple levels, each column is sized to its longest content, and spanning annotations that are still longer than the sum of the columns that they span grow them further, adding to each equally.
- Several levels, with multiple spanning annotations:
-
|[ xx ]|[ annotation spanning bases ]| |[ a1 ]|[ annotation-2 ]|[ a3 ]| |[lengthy annotation spanning base content]| |[ base 1 ]|[ base 2 ]|[ base 3 ]|
When there are multiple spanning annotations, those that span fewest bases are processed first. In this case, the green one, which spans two bases, is processed before the orange one, which spans three. Changing this order would change the distribution of space.
To help identify which spanning annotation is responsible for which extra spacing, in this diagram the color of the text in each spanning annotation is matched with the background color of spacing it adds to other boxes.
3.1.2. Block-axis Interlinear Layout
Define the extent to which vertical-align affects these ruby boxes. See Issue 4987.
Each base container is then sized and positioned to contain exactly all of its ruby bases’ margin boxes—and all their associated inter-character ruby annotation margin boxes, if any—as well as the base and annotation containers of any descendant ruby containers also participating in this inline formatting context. (If a base container has no in-flow content, it is sized and positioned as if it contained a single empty ruby base.)
Each interlinear annotation container is sized and positioned to contain exactly all of its ruby annotations’ margin boxes as well as the base and annotation containers of any descendant ruby containers also participating in this annotation level’s inline formatting context. (If an annotation container has no in-flow content, it is sized and positioned as if it contained a single empty ruby annotation.) These annotation containers are then stacked outward over or under (depending on ruby-position) their corresponding base container, without any intervening space, thus determining the block-axis positioning of the ruby annotations with respect to their ruby bases.
Should block-axis margins collapse? This makes layout more robust, but is inconsistent with how inlines behave along the inline-axis.
3.2. Inter-character Ruby Layout
Inter-character annotations have special layout. Inter-character ruby annotation boxes are spliced into and measured as part of the layout of the base level. Each ruby annotation is inserted to the right of the ruby base it is paired with; a spanning inter-character annotation is placed after the rightmost of all the bases that it spans. Inter-character ruby annotations are laid out exactly like inline blocks, except as described below.
Note: As per the definition of inter-character, inter-character annotations always have a vertical-rl writing-mode, and only exist in horizontal ruby containers.
Each ruby annotation is placed immediately to the right of the relevant ruby base, before any inter-base white space (or inter-segment white space). If multiple inter-character ruby annotation boxes are placed against the same ruby base, their margin boxes are stacked rightwards without intervening space, in increasing level order.
If the automatic height of the ruby annotation box’s content area would be shorter than the height of the content box of the ruby base after which it is placed, its content box height is increased to match that height exactly.
The alignment of the ruby annotation box depends on the ruby-align property on the ruby annotation:
- If ruby-align is start, the top edge of the ruby annotation's content box is aligned with the top edge of the ruby base's content box.
- Otherwise, the center of the ruby annotation's content box is vertically aligned with the center of the ruby base's content box.
The ruby annotation container box of an inter-character annotation is sized and placed so that its content box coincides exactly with that of the ruby base container box.
Note: The size and position of inter-character ruby annotation container boxes has no effect on layout. The above definition is merely so that programmatically inquiring about them produces deterministic results.
For the purpose of alignment and column sizing (as discussed in § 3 Ruby Layout), inter-character ruby annotations are not considered to be part of the same column as the base to with they are attached; rather, they effectively form a column of their own.
3.3. Styling Ruby Boxes
Ruby bases and ruby containers are treated as inline boxes, and all properties that apply to inline boxes, unless otherwise specified, also apply to them in the same way. However, the line-relative shift values of vertical-align (top, bottom) must be ignored (treated as zero).
All properties that apply to inline boxes, unless otherwise specified, also apply to ruby annotations in the same way, except line-height, which does not apply. Also, the line-relative shift values of vertical-align (top, bottom) must be ignored (treated as zero).
Neither the margin, padding, border properties nor the any properties that do not apply to inline boxes apply to base containers or annotation containers. Additionally, line-height does not apply to annotation containers.
The UA is not required to support any of the background properties or outline properties, or any other property that illustrates the bounds of the box on ruby base container boxes or ruby annotation container boxes. The UA may implement these boxes simply as abstractions for inheritance and control over the layout of their contents.
3.4. Breaking Across Lines
When there is not enough space for an entire ruby container to fit on the line, the ruby may be broken wherever all levels simultaneously allow a break. (See CSS Text 3 § 5 Line Breaking and Word Boundaries for details on line breaking.) Ruby most often breaks between base-annotation sets, but if the line-breaking rules allow it, can also break within a ruby base (and, in parallel, its associated ruby annotation boxes).
Whenever ruby breaks across lines, ruby annotations must stay with their respective ruby bases. The line must not break between a ruby base and its annotations, even in the case of inter-character annotations.
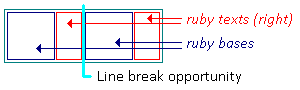
inter-character ruby line breaking opportunity
After line-breaking, each fragment is laid out independently, and ruby alignment takes place within each fragment.
3.4.1. Breaking Between Bases
In typical cases, ruby base boxes and ruby annotation boxes are styled to forbid internal line wrapping and do not contain forced breaks. (See Appendix A.) In such cases the ruby container can only break between adjacent ruby bases, and only if no ruby annotations span those ruby bases.
Ruby line breaking opportunity
Whether ruby can break between two adjacent ruby bases is controlled by normal line-breaking rules for the base text, exactly as if the ruby bases were adjacent inline boxes. (The annotations are ignored when determining soft wrap opportunities for the base level.)
< ruby > 蝴< rt > hú</ rt > 蝶< rt > dié</ rt >
Inter-base white space is significant for evaluating line break opportunities between ruby bases. As with white space between inlines, it collapses when the line breaks there, following the rules detailed in CSS Text 3 § 4.1 The White Space Processing Rules. Similarly, annotation white space is also trimmed at a line break.
< ruby >< rb > one</ rb > < rb > two</ rb > < rt > 1</ rt > < rt > 2</ rt ></ ruby >
Due to the space, the line may break between “one” and “two“. If the line breaks there, that space—and the space between “1” and “2”—disappears, in accordance with standard CSS white space processing rules.
3.4.2. Breaking Within Bases
For longer base texts, it is sometimes appropriate to allow breaking within a base-annotation pair. For example, if an English sentence is annotated with its Japanese translation, allowing the text to wrap allows for reasonable line breaking behavior in the paragraph.
Insert scanned example so people don’t think this is just the ramblings of an insane spec-writer.
Line-breaking within a ruby base is only allowed if the white-space property of the ruby base and all its parallel annotations allow it, and there exists a soft wrap opportunity within (i.e. not at the start or end) the content of each base/annotation box. Since there is no structural correspondence between fragments of content within ruby bases and annotations, the UA may break at any set of opportunities; but it is recommended that the UA attempt to proportionally balance the amount of content inside each fragment.
There are no line breaking opportunities within inter-character annotations.
3.5. Bidi Reordering
The Unicode bidirectional algorithm reorders logically-stored text for visual presentation when characters from scripts of opposing directionalities are mixed within a single paragraph.
To preserve the correspondence of ruby annotations to their respective ruby bases, a few restrictions must be imposed:
- The contents of a ruby base or ruby annotation must remain contiguous.
- Ruby annotations must be reordered together with their ruby bases.
- All ruby bases spanned by a single ruby annotation must remain contiguous.
To this end,
-
Bidi isolation is forced on all internal ruby boxes and the ruby container:
the normal and embed values of unicode-bidi compute to isolate,
and bidi-override computes to isolate-override.
Note: This means that implicit bidi reordering does not work across ruby bases, so authors will need to ensure that the ruby container’s declared directionality does indeed match its contents.
- During layout, ruby segments are ordered within the ruby container by the direction property of their ruby container.
-
Within a segment, ruby bases and ruby annotations that are not merged are ordered within their respective containers
by the direction property of the segment’s ruby base container. Merged annotations are ordered
by the direction property of their annotation container,
exactly as if they were a sequence of inline boxes within their annotation container.
Note: This means the direction property on ruby annotation containers is ignored for the purpose of layout of non-merged annotations. However, it can still inherit into the container’s children and thereby affect the inline base direction of any ruby annotations it contains.
As with other inline-level content, the bidi reordering of internal ruby boxes happens after line-breaking so that content is divided across lines according to its logical order.
Note: It could be useful to adjust these rules slightly so that when ruby-merge is merge on a particular annotation container, bidi isolation is not forced onto the individual annotations, enabling them to be processed together. However, this would add complexity to implementations, which does not seem justified in the absence of demand to handle this situation. Anyone with a need for this to be handled is encouraged to contact the CSS Working Group.
See [CSS3-WRITING-MODES] for a more in-depth discussion of bidirectional text in CSS.
3.6. Line Spacing
The line-height property controls spacing between lines in CSS. When inline content on line is shorter than the line-height, half-leading is added on either side of the content, as specified in CSS Inline Layout 3 § 5 Logical Heights and Inter-line Spacing.
In order to ensure consistent spacing of lines, documents with ruby typically ensure that the line-height is large enough to accommodate ruby between lines of text. Therefore, ordinarily, ruby annotation containers and ruby annotation boxes do not contribute to the measured height of a line’s inline contents; any alignment (see vertical-align) and line-height calculations are performed using only the ruby base container, exactly as if it were a normal inline.
However, if the line-height specified on the ruby container is less than the distance between the top of the top ruby annotation container and the bottom of the bottom ruby annotation container, then additional leading is added on the appropriate side(s) of the ruby base container such that if a block consisted of three lines each containing ruby identical to this, none of the ruby containers would overlap.
Note: This does not ensure that the ruby annotations remain within the line box. It merely ensures that if all lines had equal spacing and equivalent amounts and positioning of ruby annotations, there would be enough room to avoid overlap.
Authors should ensure appropriate line-height and padding to accommodate ruby, and be particularly careful at the beginning or end of a block and when a line contains inline-level content (such as images, inline blocks, or elements shifted with vertical-align) taller than the paragraph’s default font size.
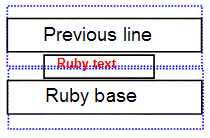
Ruby annotations will often overflow the line; authors should ensure content over/under a ruby-annotated line is adequately spaced to leave room for the ruby.
Note: More control over how ruby affects alignment and line layout will be part of the CSS Line Layout Module Level 3. Note, it is currently in the exploratory stages of development; descriptions of new features should not yet be relied upon.
4. Ruby Formatting Properties
The following properties are introduced to control ruby positioning, text distribution, and alignment.
4.1. Ruby Positioning: the ruby-position property
| Name: | ruby-position |
|---|---|
| Value: | [ alternate || [ over | under ] ] | inter-character |
| Initial: | alternate |
| Applies to: | ruby annotation containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | discrete |
This property controls position of the ruby annotation with respect to its base. Values have the following meanings:
- alternate
-
Different levels of annotations alternate between over and under.
If the annotation container is the first level of annotation in its ruby segment, or if all prior levels are inter-character, then alternate, either on its own or in combination with over, behaves the same as over, while alternate in combination with under behaves the same as under.
Otherwise, if the previous level of interlinear annotation is over, alternate behaves like under, and vice versa. (In this case, whether alternate is specified alone or in combination with over or under makes no difference.)
- over
-
The ruby annotation appears line-over the base.
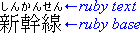
Ruby over Japanese base text in horizontal layout
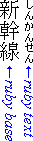
Ruby to the right of Japanese base text in vertical layout
- under
-
The ruby annotation appears line-under the base.
This is a relatively rare setting used in ideographic East Asian writing systems,
most easily found in educational text.
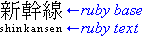
Ruby under Japanese base text in horizontal layout
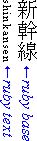
Ruby to the left of Japanese base text in vertical layout
- inter-character
-
If the writing mode of the enclosing ruby container is vertical,
this value has the same effect as over.
Otherwise, the ruby annotation becomes an inter-character annotation. The annotation appears on the right of the base in horizontal text. This forces the computed value of writing-mode of the ruby annotation children of this ruby annotation container to be vertical-rl.
Note: The computed value of writing-mode on the ruby annotation container itself is not affected. This is to avoid circular dependencies between computed values on the writing-mode, display, and ruby-position properties on the same element.
This value is provided for the special case of traditional Chinese as used especially in Taiwan: ruby (made of bopomofo glyphs) in that context appears vertically along the right side of the base glyph, even when the layout of the base characters is horizontal:
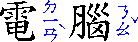
“Bopomofo” ruby in traditional Chinese (ruby annotation shown in blue for clarity) in horizontal layout
Note: As inheritance works on the element tree without accounting for anonymous boxes created for ruby layout, when using inter-character annotations authors need to be careful to avoid markup patterns involving an element-based ruby annotation container, an anonymous ruby annotation, and further descendant elements, as those descendants would inherit their writing mode from the ruby annotation container, and not from the ruby annotation whose writing-mode has been changed to vertical-rl.ruby
{ ruby-position : inter-character; } < ruby > base< rtc >< em > problematic</ em > annotation</ ruby > In the above markup, an anonymous ruby annotation box is created as a child of the
<rtc>element to wrap the whole “problematic annotation”. Since it is a child of an annotation container whose ruby-position is inter-character, its writing-mode will be vertical-rl, which is expected. However, the<em>element inherits its writing-mode directly from the<rtc>element, which has not been forced to vertical-rl.In this example, the explicit ruby annotation container element was not necessary, so using a ruby annotation element instead would avoid the problem:
< ruby > base< rt >< em > problematic</ em > annotation</ ruby > If an explicit ruby annotation container element is needed, then using a ruby annotation element as well would also address the problem:
< ruby > base< rtc >< rt >< em > problematic</ em > annotation</ ruby >
Annotation containers that are not inter-character annotations are called interlinear annotations.
If multiple ruby annotation containers have the same ruby-position, they stack outwards from the base text.
4.2. Sharing Annotation Space: the ruby-merge property
| Name: | ruby-merge |
|---|---|
| Value: | separate | merge | auto |
| Initial: | separate |
| Applies to: | interlinear ruby annotation containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
This property controls how ruby annotation boxes should be rendered when there are more than one in a ruby container box: whether each pair should be kept separate, the annotations should be merged and rendered as a group, or the separation should be determined based on the space available.
Note: Inter-character annotations are always separate, and this property does not apply.
Possible values:
- separate
-
Each ruby annotation box is rendered within
the same column(s) as its corresponding base box(es),
i.e. without overlapping adjacent bases on either side.
This style is called “mono ruby” in [JLREQ].

ruby-merge: separate with center alignment - merge
-
All ruby annotation boxes within the same ruby segment on the same line are concatenated
as inline boxes within their annotation container,
and laid out in a single anonymous ruby annotation box spanning all their associated ruby base boxes.
When laid out on a single line,
this style renders similar to “group ruby” in [JLREQ].
However, when it breaks across lines, ruby annotations are kept together with their respective ruby bases.
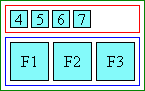
ruby-merge: merge with center alignment The following two lines render the same if both characters fit on one line:< p >< ruby > 無常< rt > むじょう</ ruby > < p >< ruby style = "ruby-merge:merge" >< rb > 無< rb > 常< rt > む< rt > じょう</ ruby > However, the second one renders the same as ruby-position: separate when the two bases are split across lines.
- auto
-
The user agent may use any algorithm to determine how each ruby annotation box
is rendered to its corresponding base box,
with the intention that if all annotations fit over their respective bases,
the result is identical to separate,
but if some annotations are wider than their bases
the space is shared in some way
to avoid imposing space between bases.
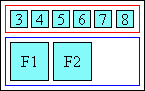
ruby-merge: auto with center alignment Note: This behavior is intended for compound words, see “Jukugo Ruby” in “What is ruby?”. [QA-RUBY]There are various conventions for rendering this type of ruby, see Placement of Jukugo-ruby in [SIMPLE-RUBY], Positioning of Jukugo-ruby in [JLREQ], and 4.12.3(c) 熟語ルビの処理 in [JISX4051] for examples of varying complexity.
The simplest of these is to render as separate if all ruby annotation boxes fit within the advances of their corresponding base boxes, and render as merge otherwise.
Note: Text does not shape or form ligatures across ruby annotations or bases, even merged ones, due to bidi isolation. See § 3.5 Bidi Reordering and CSS Text 3 § 7.3 Shaping Across Element Boundaries.
4.3. Ruby Text Distribution: the ruby-align property
| Name: | ruby-align |
|---|---|
| Value: | start | center | space-between | space-around |
| Initial: | space-around |
| Applies to: | ruby bases, ruby annotations, ruby base containers, ruby annotation containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
This property specifies how text is distributed within the various ruby boxes when their contents do not exactly fill their respective boxes. Note that space distributed by ruby-align is unrelated to, and independent of, any space distributed due to justification.
For inter-character annotations, this property can also affect the alignment of the box itself (see § 3.2 Inter-character Ruby Layout). It otherwise only affects the alignment of content within the box, not the size or position of the box itself.
Values have the following meanings:
- start
-
The ruby content is aligned with the start edge of its box.
"Katatsuki ruby" (肩付きルビ) is close to, but not quite the same as, this start value. In particular, its behavior when overhanging its base can differ from start alignment depending on surrounding context, see JLREQ. Also, it’s only ever used in vertical writing, and the JLTF considers it not particularly important, so it may not be worth the effort to make this value smart enough to deal with katatsuki ruby. If start is needed for some other purpose, we should keep it. Otherwise, maybe just drop it?
- center
- The ruby content is centered within its box.
- space-between
- The ruby content expands as defined for normal text justification (as defined by text-justify), except that if there are no justification opportunities the content is centered.
- space-around
- As for space-between except that there exists an extra justification opportunities whose space is distributed half before and half after the ruby content.
The distribution of space can be controlled via text-justify. [CSS-TEXT-3]
Content in ruby bases and ruby annotations, except those that span due to ruby-merge: merge, is aligned within its box based on the value of ruby-align on that box. Content in merged annotations is aligned within the ruby annotation container based on the value of ruby-align on the annotations container, ignoring the value of ruby-align on the individual ruby annotations.
What if a merged annotation causes the ruby segment to be wider? Does it cause each base to grow as if it were spanning them, as currently specified? This does not allow e.g. centering the text in a multi-base base container when its merged annotation is longer. Instead, maybe we should allow ruby-merge to apply to base containers as well, but this would require us either to allow a single base to span multiple annotations (if the base is merged but some annotation levels are not), or to require that if the base is merged, then all annotation levels must be merged as well.
The way content is aligned when ruby-merge is auto is up to the user agent, but must be identical to that of ruby-merge: separate when all annotations fit over their respective bases.
4.4. Ruby Text Decoration
Text decoration does not propagate from the base text to the annotations.
When text decoration is specified on an ancestor of the ruby, it is drawn across the entire content area of the ruby base container, including any extra space added on either side of the ruby base contents to accommodate long annotations. When text decoration is specified on a ruby base itself, this extra space is not decorated, similar to how a box’s own padding is not decorated when text decoration is specified directly on that box. [CSS3-TEXT-DECOR]
Text decoration may be specified directly on ruby base containers and ruby annotation containers: in such cases it is propagated to all of the container’s bases or annotations (respectively), and is also drawn between them for continuity.
The positions of ruby annotations may be adjusted to avoid potential conflicts with overline and underline decorations applied to the base text. In the basic case of consistent font size and baseline alignment, an underline or overline is positioned between the base level and any annotations on that side.
This section needs some clarification about drawing decorations between the content of adjacent bases/annotations. Depends on if those boxes are as wide as their column or not.
5. Edge Effects
5.1. Overhanging Ruby: the ruby-overhang property
| Name: | ruby-overhang |
|---|---|
| Value: | auto | none |
| Initial: | auto |
| Applies to: | ruby annotation containers |
| Inherited: | yes |
| Percentages: | n/a |
| Computed value: | specified keyword |
| Canonical order: | per grammar |
| Animation type: | by computed value type |
The ruby-overhang property controls whether ruby annotations may overlap adjacent text outside the ruby container. Values have the following meanings:
- auto
-
When a ruby annotation container is longer than
its corresponding ruby base container,
the ruby annotation container may
partially overlap adjacent boxes.
Whether, how much, and under which conditions to overhang are determined by the UA.
- none
- A ruby annotation container is never allowed to extend past the ruby annotation container.
When ruby annotations are not allowed to overhang, the ruby container behaves like a traditional inline box, i.e. only its own contents are rendered within its boundaries and adjacent elements do not cross the box boundary:
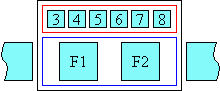
Simple ruby whose text is not allowed to overhang adjacent text
However, if a ruby annotation container is allowed to overhang, neighbouring content may overlap the ruby container box, allowing its ruby annotation(s) to partially render over/under surrounding inline-level content. Overhang is only allowed to the extent that it does not cause collisions between the neighboring content and the ruby container’s annotation boxes or its overlapped base’s contents.
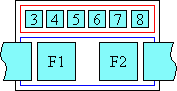
Simple ruby whose text is allowed to overhang adjacent text
Note: Whether ruby annotations related to a ruby base can overhang another ruby base is controlled by ruby-merge.
Typically, the alignment of the contents of the base or the annotation is not affected by overhanging behavior: alignment and space distribution (see ruby-align) is achieved the same way regardless of the overhang allowance, and is computed before the space available for overlap is determined. However, UAs may consider allowed overhang when determining space distribution and/or alignment of annotations and bases.
I suspect overhanging interacts with alignment in some cases; might need to look into this later.
5.2. Line-edge Alignment
When a ruby annotation box that is longer than its ruby base is at the start or end edge of a line, the user agent may force the side of the ruby annotation that touches the edge of the line to align to the corresponding edge of the base. This type of alignment is described by [JLREQ].
This level of the specification does not provide a mechanism to control this behavior.
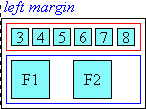
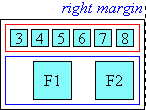
Line-edge alignment
Appendix A: Sample Style Sheets
This section is informative.
A.1 Default UA Style Sheet
The following represents a default UA style sheet for rendering HTML and XHTML ruby markup as ruby layout:
ruby{ display : ruby; } rp{ display : none; } rbc{ display : ruby-base-container; } rtc{ display : ruby-text-container; } rb{ display : ruby-base; white-space : nowrap; } rt{ display : ruby-text; } ruby, rb, rt, rbc, rtc{ unicode-bidi : isolate; } rtc, rt{ font-variant-east-asian : ruby; /* See [[CSS-FONTS-3]] */ text-justify: ruby; /* See [[CSS-TEXT-4]] */ text-emphasis: none; /* See [[CSS-TEXT-DECOR-3]] */ white-space: nowrap; line-height : 1 ; } rtc, :not ( rtc) > rt{ font-size : 50 % ; } rtc:lang ( zh-TW), :not ( rtc) > rt:lang ( zh-TW), rtc:lang ( zh-Hanb), :not ( rtc) > rt:lang ( zh-Hanb), { font-size : 30 % ; } /* bopomofo */
Note: Authors should not use the above rules: a UA that supports ruby layout should provide these by default.
UAs implementing a user-controlled “minimum font size” feature should consider scaling that minimum down for ruby annotations.
A.2 Inlining Ruby Annotations
The following represents a sample style sheet for rendering HTML and XHTML ruby markup as inline annotations:
ruby, rb, rt, rbc, rtc, rp{ display : inline; white-space : inherit; font : inherit; text-emphasis : inherit; }
A.3 Generating Parentheses
Unfortunately, because Selectors cannot match against text nodes, it’s not possible with CSS to express rules that will automatically and correctly add parentheses to unparenthesized ruby annotations for all possible ruby markup patterns in HTML. (This is because HTML ruby allows implying the ruby base from raw text without a corresponding element.)
However, these rules will add parentheses around each annotation sequence
in cases where either <rb> or <rtc> is used rigorously:
/* Parens around <rtc> */ rtc::before{ content : "(" ; } rtc::after{ content : ")" ; } /* Parens before first <rt> not inside <rtc> */ rb + rt::before, rtc + rt::before{ content : "(" ; } /* Parens after <rt> not inside <rtc> */ rb ~ rt:last-child::after, rt + rb::before{ content : ")" ; } rt + rtc::before{ content : ")(" ; }
Alternatively, if it is known that a purely alternating style of markup is used
(
/* Parens around each <rt> */ rt::before{ content : "(" ; } rt::after{ content : ")" ; }
6. Glossary
- Bopomofo or Zhuyin Fuhao (Chinese: ㄅㄆㄇㄈ, 注音符號, or 注音符号)
-
Characters and tone markings developed for use as phonetics in Chinese, especially standard Mandarin. These are often, but not exclusively, used for ruby annotations.

Example of Bopomofo used as phonetic inter-character annotations in Chinese
Bopomofo tone marks are spacing characters that occur (in memory) at the end of each bopomofo syllable. They are typically displayed in a separate track to the right of or above the other bopomofo characters, and the position of the tone mark depends on the number of characters in the syllable. The neutral tone mark, however, is placed before (and in line with) the bopomofo, not alongside it.
Note: The user agent and font subsystem are responsible for ensuring the correct relative alignment and positioning of glyphs, including bopomofo tone marks, when displaying text—whether the text occurs in ruby annotations or as normal inline content. Such glyph placement is not a function of CSS ruby layout.
Bopomofo letters belong to the
BopomofoUnicode script (and are currently mapped in the U+3100–312F and U+31A0–31BF blocks); the Bopomofo tone marks are U+02C9 (ˉ), U+02CA (ˊ), U+02C7 (ˇ), U+02CB (ˋ), U+02EA (˪), U+02EB (˫), U+02D9 (˙). Collectively these are all considered Bopomofo characters for the purpose of CSS. - Hanja (Korean: 漢字)
- Subset of the Korean writing system that utilizes ideographic characters borrowed or adapted from the Chinese writing system. Also see Kanji.
- Hiragana (Japanese: 平仮名)
- Japanese syllabic script, or character of that script. Rounded and cursive in appearance. Subset of the Japanese writing system, used together with kanji and katakana. In recent times, mostly used to write Japanese words when kanji are not available or appropriate, and word endings and particles. Also see Katakana.
- Ideograph
- A character that is used to represent an idea, word, or word component, in contrast to a character from an alphabetic or syllabic script. The most well-known ideographic script is used (with some variation) in East Asia (China, Japan, Korea,...).
- Kana (Japanese: 仮名)
- Collective term for hiragana and katakana.
- Kanji (Japanese: 漢字)
- Japanese term for ideographs; ideographs used in Japanese. Subset of the Japanese writing system, used together with hiragana and katakana. Also see Hanja.
- Katakana (Japanese: 片仮名)
- Japanese syllabic script, or character of that script. Angular in appearance. Subset of the Japanese writing system, used together with kanji and hiragana. In recent times, mainly used to write foreign words. Also see Hiragana.
Acknowledgments
This specification would not have been possible without the help from:
David Baron, Robin Berjon, Susanna Bowen, Stephen Deach, Martin Dürst, Hideki Hiura (樋浦 秀樹), Masayasu Ishikawa (石川雅康), Taichi Kawabata, Chris Pratley, Xidorn Quan, Takao Suzuki (鈴木 孝雄), Frank Yung-Fong Tang, Chris Thrasher, Masafumi Yabe (家辺勝文), Boris Zbarsky, Steve Zilles.
Special thanks goes to the previous editors: Michel Suignard and Marcin Sawicki of Microsoft, and Richard Ishida of W3C.
Changes
This section documents the changes since previous publications.
Changes since the 2 December 2021 WD
- Made the computed-value adjustment of writing-mode on inter-character annotations apply to the ruby annotation box rather than the ruby annotation container box.
- Added
zh-Hantto rule applying font-size: 30% to ruby annotations in HTML. - Added
text-justify: rubyto the UA default style sheet. (Issue 771 Issue 779)
Changes since the 29 April 2020 WD
- Added alternate keyword to ruby-position and made it the initial value.
- Renamed collapse value of ruby-merge to merge. (Issue 5004)
- Defined visibility: collapse to explicitly an annotation the same way annotations are hidden. (Issue 5927)
- Specified more precisely which properties apply to the various ruby display types (§ 3.3 Styling Ruby Boxes) and defined ruby, ruby base, and ruby annotation boxes to behave the same as regular inline boxes except as otherwise specified. (Issue 4935, Issue 4936, Issue 4976, Issue 4979)
- Substantially revamped § 3 Ruby Layout to more clearly define interlinear and inter-character ruby layout and their interaction with ruby-align. Inter-character ruby is now based on inline block layout, and its interaction with interlinear ruby is also now well-defined. Inline-axis space distribution for interlinear ruby is now more precisely defined for spanning annotations (modeled on max-content grid tracks).
- Defined handling of nested ruby by accounting for their base and annotation containers in the block-axis sizing of interlinear ruby. (Issue 4986, Issue 4980)
- Specified more precisely how ruby-align works.
- Loosened requirement that ruby overhang not affect the alignment of ruby contents, added requirement that it not cause ruby content to collide with adjacent content.
- Clarified interaction of bidi reordering and merged annotations. (§ 3.5 Bidi Reordering)
- Tightened up normative prose throughout.
- Improved introduction, examples, and other informative text.
Note: There remain many open issues, see Disposition of Comments and the newer issues tracked in GitHub.
Changes since the 5 August 2014 WD
- Add back ruby-overhang: auto | none for basic control over ruby overhang behavior.
- Harmonize inlinification with the CSS Display Module.
- Allow UA to shift ruby/emphasis marks if they conflict with underlines/overlines.
- Disable auto-hiding when the computed value of ruby-merge is
collapse. - Tweak the default style sheet.
- Add section defining interaction with text decoration.
- Defer the right and left values of ruby-position to the next level.
- Change ruby pairing rules to only apply spanning on anonymous annotations (i.e. content directly contained by an
rtc). - Pair excess bases / annotations with auto-generated empty anonymous bases / annotations.
- Apply ruby-position to ::first-line. (Issue 2998)
- Clarify containing block of ruby boxes and contents is, as in the case of other inline boxes, the nearest block container.
- Clarify handling of misparented internal table elements.
- Trim leading/trailing white space in ruby containers, base base containers, and annotation containers to prevent it from interfering with pairing.
- Define layout effect of empty base and annotation containers.
- Disable margins, padding, and borders on ruby base containers and ruby annotation containers (but not on ruby bases and ruby annotations).
Changes since the 19 September 2013 WD
- Rewrite anonymous box generation rules and white space handling rules, defined specialized pairing of anonymous white space boxes.
- Take nested ruby handling out of pairing. (Will be handling it via sizing/layout.)
- Define bidi layout of ruby structures.
Changes since the 30 June 2011 WD
- Remove
ruby-spanand mentions ofrbspan. - Explicit spanning is not used in HTML ruby in favor of implicit spanning. This can’t handle some pathological double-sided spanning cases, but there seems to be no requirement for these at the moment. (For implementations that support full complex XHTML Ruby, they can imply spanning from the markup the same magic way that we handle cell spanning from tables. It doesn’t seem necessary to include controls this in Level 1.)
- Defer
ruby-overhangandruby-align: line-endto Level 2. - It’s somewhat complicated, advanced feature. Proposal is to make this behavior UA-defined and provide some examples of acceptable options.
- Close issue requesting
display: rp: usedisplay: none. - The Internationalization WG added an issue
requesting a display value for
rpelements. They’re supposed to be hidden whenrubyis displayed as ruby. But this is easily accomplished already withdisplay: none. - Change ruby-position values to match text-emphasis-position.
- Other than inter-character, which we need to keep, it makes more sense to align ruby positions with text-emphasis-position, which can correctly handle various combinations of horizontal/vertical preferences.
- Remove unused values of ruby-align.
- left, right, and end are not needed.
- Replace auto, distribute-letter, and distribute-space from ruby-align with space-between and space-around.
- The auto value relied on inspecting content to determine behavior;
this can be avoided by just using space-around with standard justification rules
(which allow spacing between CJK but not between Latin).
Replaced distribute-letter and distribute-space with space-between and space-around for consistency with distribution keywords in [CSS-FLEXBOX-1] and [CSS-ALIGN-3] and to avoid any links to the definition of
text-justify: distribute. - Added ruby-merge property to control jukugo rendering.
- This is a stylistic effect, not a structural one; the previous model assumed that it was structural and suggested handling it by changing markup. :(
- Remove inline from ruby-position.
- This is do-able via
display: inlineon all the ruby-related elements, see Appendix A. - Added Default Style rules
- As requested by Internationalization WG.
- Wrote anonymous box generation rules
- And defined pairing of bases and annotations. Should now handle all the crazy proposed permutations of HTML ruby markup.
- Defined layout of ruby
- Defined in detail space distribution, white space handling, line breaking, line stacking, etc. Open issue left for bidi.
Privacy Considerations
No new privacy considerations have been reported on this specification.
Security Considerations
No new security considerations have been reported on this specification.