In this document we present a method for writing, marking-up, and analyzing conformance requirements in technical specifications.
This is the first publication of this document as a Working Group Note by the Mobile Web Initiative Test Suites Working Group. This publication results from the
collaboration between the Mobile Web Initiative Test Suites
Working Group and the Web Applications Working Group on the
development of test suites for the Widgets family of
specifications.
Introduction
In this document we present a method for writing, marking-up, and analyzing conformance requirements in technical specifications.
We argue that the method yields specifications whose conformance requirements are testable: that is, upon applying the method, parts of what is written in the specification can be converted into a test suite without requiring, for instance, the use of a formal language.
The method was derived from a collaboration between the W3C's Mobile Web Initiative: Test Suites Working Group and the Web Applications Working Group. This collaboration aimed to improve the written quality and testability of various specifications. The applications, limitations, as well as possible directions for future work that could refine this method are described in this document.
Common Mistakes
When working on a specification, there are common mistakes an editor can make when writing
conformance requirements that makes them difficult, if not impossible, to test. For technical specifications, the testability of a conformance requirement is imperative: conformance requirements eventually become the test cases that implementations rely on to claim conformance to a specification. If no implementation can claim conformance, or if aspects of the specification are not testable, then the probability of a specification becoming a ratified standard, and, more importantly, achieving interoperability among implementations, is significantly reduced.
The most common mistakes that editors make when writing conformance requirements include, but are not limited to:
-
Creating
conformance requirements for products that don’t have
behavior, e.g. “an XML file must be well-formed.” — this cannot
be tested since it doesn’t say what the outcome is on
that condition.
-
Using
a passive voice for describing the behavior, e.g.
“an invalid XML file must be
ignored” — this hides what
product is supposed to follow the prescribed
behavior.
-
Using
under-defined behaviors, e.g. “a user agent
must reject malformed XML” without defining the algorithmic process that is to
“reject” something —
this makes it impossible to define the outcome of the
testable assertion.
The Method
Because conformance requirements are intertwined as part of the text of a specification (as sentences, paragraphs, dot points, etc.), it can be difficult to detect the various common mistakes. For this reason, the first step in our method is to identify and mark-up (using HTML) various structural components that constitute a conformance requirement. Understanding these structural components is important, because it is that structure that determines the testability of a conformance requirement. We discuss the structure of conformance requirements, as well as how to mark them up, in more detail below.
Once conformance requirements have been marked up into their component parts, then they can be extracted and analyzed outside the context of the specification. Seeing a conformance requirement out of context can often expose inconsistencies and redundancies that may otherwise been difficult for the editor, or an independent reviewer, to identify. The ability to extract conformance requirements from a specification also allows them to be used in other contexts, such as in the creation of a test suite.
The general process that constitutes the method is as follows:
-
Markup conformance requirements that need to be tested and give them a stable identifier that will persist across drafts of the specification.
-
Extract the conformance requirements and examine them independently of the specification. Fix common mistakes and remove any duplicates.
-
Establish a quality assurance process for both creating and verifying the test cases. In our case, this included providing a set of tools, templates, and methods explaining how to build useful test cases for the said specification (see [[WIDGETS-PC-TESTS]]). During the creation of the test suite for the [[WIDGETS]] specification, we also imposed a rule within those working on the test suite that a test case had to be independently verified before being committed into the final test suite. Although defective test cases still made it into the test suite, as more implementers worked their way through the test suite, the more bugs were found and fixed (both in the specification and in the test suite).
-
Create test cases and corresponding testable assertions. The act of converting prose into a computational form (a test case) can also help expose redundancies, ambiguities, and common mistakes. Bind the testable assertions to a conformance requirement via a stable identifier.
-
Build at least one test case for each conformance requirement. On average, our test suite contains 3 test cases per conformance requirement, with some assertions having 10 or more test cases.
-
Compare the results of running these test cases on existing implementations to find bugs in the specification or in the test suite. For example, if one finds that all implementations are failing a test case, it might mean that the test case is defective.
- Republish the specification, call for implementations, and gather feedback. Fix any issues that were identified and republish the specification if necessary.
As the Web Applications Working Group learned, it can be problematic to enter the W3C’s Candidate Recommendation phase without having a complete and thoroughly verified test suite: because this method was mostly applied during Candidate Recommendation, so many redundancies and issues where found that the specification had to drop back to Working Draft. This demonstrated that the method was effective, but needs to be applied as early as possible in the specification writing process.
Relationship to the standardization process
The standards organization, which in this case is the W3C, plays a significant role in relation to the method: the standards organization provides access to a community of experts, as well as the tools that facilitate the interaction and communication between actors and the deliverables that are the outputs of a working group.
Deliverables include the specification, testable assertions, and test cases that constitute the test suite. Actors include editors, test creators, QA engineers, implementers, and specification reviewers. Actors, which in many cases will be the same person in multiple roles, literally provide the intelligence that improves the quality of deliverables.
The tools provided by the standards organization harness the collective intelligence of actors (by capturing their interactions and communications). Some of the tools provided by the W3C include CVS, IRC, a web server, phone bridge, the technical report repository, publication rules checker, issue tracking software, and a mailing list. The standards organization also provides the legal framework that allows multiple competing entities to share intellectual property and collaborate with each other.
The method simply taps into the community-driven process that is standardization, which, through its process, is structured to produce high-quality peer-reviewed work. The following diagram visualizes how actors communicate with each other to improve the quality of various deliverables through tools provided by the standards organization. As can be seen, interaction between actors, tools, and deliverables form feedback loops that serve to improve the work being produced by the working group.
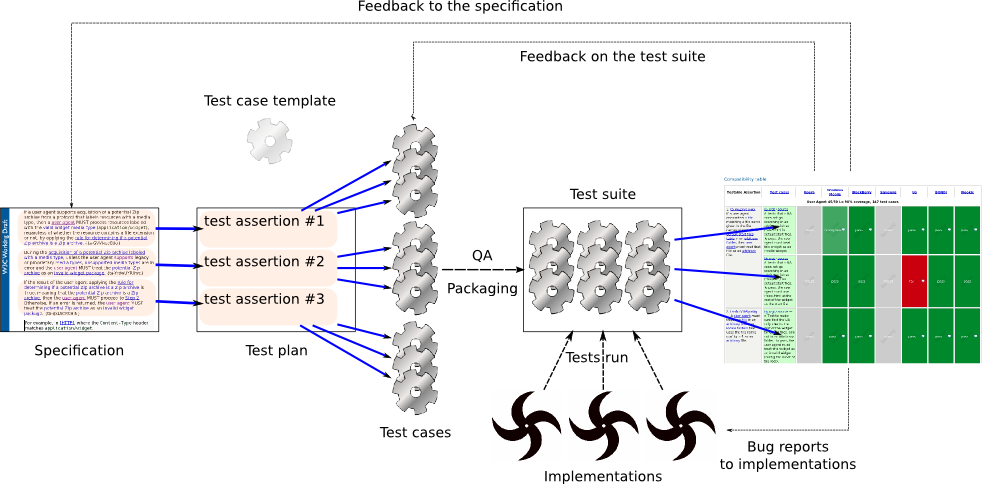
Value of applying the method
An economic case can be made for identifying and removing redundant conformance requirements from a specification: consider that an average size specification can have around 50 conformance requirements, and each conformance requirement will require one or more test cases. Each test case will require a testable assertion, which may be either written in prose (e.g., “to pass, a must equal b.”) or expressed computationally (e.g., if(a===b)). In terms of resource allocation, someone needs to either manually create or computationally generate the test cases. Someone then needs to verify if each test case actually tests the conformance requirement, and, where it doesn’t, fixes need to be made to either the test case or to the specification.
Eventually, QA engineers will need to run the test cases and conformance violations will need to be reported by filling bug reports. Even in a pure computational setting, having redundant tests in a test suite still results in wasted CPU cycles every time a build of software is run against the test suite. If redundant tests build up, it can have a significant impact on quality assurance processes where it can take hours - or sometimes days - to run builds of a product through various test suites.
Simply put, a test suite for a specification should only test what is necessary for a product to conform - and no more.
It should be noted that “acid tests” (e.g., the Acid3 test) certainly have an important role in creating interoperability by exposing erroneous edge-case behavior and the limitations of implementations. But such stress tests are typically beyond the scope of a test suite for a specification.
Structural Components of a Conformance Requirement
To be testable, a conformance
requirement must contains the necessary information to create a testable assertions, as described in The Structure of a Test Assertion in the Test Assertions Guidelines [[OASIS-TAG]].
Consider the following conformance requirement from the [[WIDGETS]]
specification:
If the src attribute of the content element is absent or an empty string, then the user agent must ignore this element.
The structure of the conformance requirement can be decomposed into the following structural components:
- Product
-
A product that is supposed to follow the
requirement — in this case, the
“user agent”. (see also the definition of “classes of product” in [[QAFRAME-SPEC]])
- Strictness level
-
The strictness of the applicability of the requirement to a product — in this case, “the user agent must” do something. W3C specifications use the [RFC2119]
keywords (must, should, may, etc.) to indicate the level of requirement that is imposed
on a product.
- Prerequisites
-
An explanation of the prerequisites that need to be in place in order for the requirement
to apply — in this case, “if the src attribute of the content element is absent or an empty string”.
- Behavior
-
a
clear explanation of what the product is supposed to do
— in this case,
“ignore this element”.
- Terms
-
Keywords that are relevant to understanding how to apply the desired behavior. For instance, what it actually means to “ignore” (definitively and algorithmically) needs to be specified somewhere in the specification.
Terms take one of the three forms in a specification: an algorithm, a definition, or a statement of fact.
-
An example of an algorithm:
In the case the user agent is asked to ignore an [XML] element or node, a user agent:
-
Stops processing the current element, ignoring all of the element‘s attributes and child nodes (if any), and proceed to the
next element in the elements list.
-
Make a record that it has attempted to process an element of that
type.
An example of a definition:
A user agent is an implementation of this specification that also supports XML...
An example of a statement of fact:
A user agent will need to keep a record of all element types it has attempted to process even if they were ignored (this is to determine if the user agent has attempted to process an element of a given type already).
Having an understanding of the structural components that need to be present in every conformance requirement, an editor can then use the following conventions to mark-up their specification.
Conventions for Marking-up Conformance Requirements
Using mark-up makes it possible to
exploit the structure of conformance requirements for various purposes, particularly for analysing that conformance requirements don’t exhibit the common mistakes. Here, we describe how we made use of HTML to markup conformance requirements in the [[WIDGETS]] specifciation. However, this should be considered purely as an example that would need to be adapted to fit each specification particularities.
Consider the following conformance requirement from the [[WIDGETS]] specification, as we will make use of it in this section:
If a user agent encounters a file matching a file name given in the file name column of the default start files table in an arbitrary folder, then user agent must treat that file as an arbitrary file.
From the previous section, we know that the relevant structural components are:
- Product:
the user agent
.
- Strictness level:
must
.
- Prerequisites:
If a user agent encounters a file matching a file name given in the file name column of the default start files table in an arbitrary folder
- Behavior:
treat that file as an arbitrary file
.
- Terms:
file
, folder
, file name
, arbitrary
, default start files table.
Having identified all the component parts, our method for marking up the conformance requirement is as follows (in no particular order):
-
Isolate each conformance requirement within an appropriate HTML element, such as a p element — this isolates all the useful information into a single logical container, making it easy to extract and examine out of context. We discuss methods for extracting conformance requirements in the next section of this document.
-
Assigning a unique identifier to each conformance requirement and mark it as testable— In our case, each
conformance requirement is uniquely identified through the id attribute on the p element; the unique identifier starts by convention with ta-, which denotes it as conformance requirement, followed by a randomly generated string (e.g., <p id="ta-abc">). The uniqueness
of the id can be verified by running the HTML document through a validator.
This
same id attribute is also useful as it allows linking back to the specification
exactly to the point where the assertion is made. This proved useful during testing, where the
tester can get more context on the definitions and the spirit
of the assertion when the letter of it is not
enough.
When creating the test suite, distinguishing conformance requirements from other parts of the specification allows test cases to be grouped by conformance requirement through exploiting this identifier. In addition, examining how many test cases are grouped around a conformance requirement is useful for assessing how much of the specification has been, or needs to be, tested and verified.
Note that in the case of the [[WIDGETS]] specification, the randomly generated strings were 10 characters long (e.g., ta-qxLSCRCHlN) which proved somewhat cumbersome for people to work with. Other specifications the Working Group is working on use much shorter identifiers (two letters).
-
Explicitly identify the product to which the conformance requirement applies
— this defines how the test cases
are built in the test suite, based on how the product is supposed to
operate. The
conformance product to which the requirement applies is
marked up with a class attribute set to one of the
predefined values — in the case of the [[WIDGETS]] specification, the product was identified using a span element with a class atttribute value of product-ua. For example, “A <span class="product-ua">user agent</span>…”.
-
Identify the level of requirement for conformance — that is, use an element to explicitly mark-up [[RFC2119]]
keywords (must, should, may, etc.). Doing so is useful for identifying aspects of the specification that must be included in the test suite, and aspects in the specification that might not be worth testing (e.g., conformance requirements that make use of the RFC2119 “optional” keyword).
The
level of requirement is marked up by an emphasis element
(<em>) with a class defined to ct; this mark-up
convention also allows determining if a given paragraph of
the specification contains a requirement or
not. For example, <em class="ct">must</em>.
-
Hyperlink to the appropriate terms. For example, “encounters a <a class="term" href="#file">file</a> matching”.
The following code shows what the conformance requirement presented at the start of this section would look like once the above dot points are applied:
<p id="ta-a1">If a user agent encounters a <a
href="#file">file</a> matching a file
name given in the file name column of the <a
href="#default-start-files-table">default start files
table</a> in an <a
href="#arbitrary">arbitrary</a> <a
href="#folder">folder</a>,
then <a class="product-ua" href="#user-agent">user agent</a> <em
class="ct">must</em> treat that file as an <a
href="#arbitrary">arbitrary</a> file.</p>
Extracting Conformance Requirements
After the [[WIDGETS]] specification was marked up using the conventions described above, the conformance requirements were extracted using an XSLT style sheet which served as the basis for a review of the testability of the specification.
Over time, the XSLT style sheet was discarded in favor of using a JavaScript system. The JavaScript-based system replicates what the XSLT style sheet was doing, but then mashes the conformance requirements with an XML document that describes all the tests cases in the test suite. This allows those working on the specification and on the test suite to not only see the conformance requirements, but also what test cases have been created.
Because we wrap all conformance requirements in p elements, the actual process of extracting conformance requirements is relatively simple. We use the JQuery JavaScript library, in conjunction with a simple CSS selector, as the means to extract the conformance requirements. The CSS selector finds all p elements in the document that have an id attribute that starts with the string ta-. For example:
function processSpec(spec){
//CSS selector
var taSelector = 'p[id^="ta-"]';
//Extracted nodes
var requirements = $(spec).find(taSelector, false);
//Display the resuts...
requirements.each(function(){...}}
}
Testable Assertions and Test
Cases
The working groups found that once conformance requirements have been extracted, the work of creating test cases for a test suite was significantly simplified.
A test case is a machine processable object that is used to test one or more conformance requirements. A testable assertion, on the other hand, is a prose description of a test case intended for human testers - i.e., for a given test case, testable assertion defines exactly what the user agent needs to do (behaviorally or conditionally) to pass the test case. It is important to note that testable assertions don’t appear in a specification - they only appear in a test suite to describe a test case.
To create a test, a test writer looks at a given conformance requirement, creates a test case that matches the pre-requisites set
in the requirement, and documents the expected outcome described by
the required behavior as a testable assertion (or vice versa).
To demonstrate how testable assertions are written, again consider the following conformance requirement from the Widgets Packaging and Configuration [[WIDGETS]]
specification:
If the src attribute of the content element is absent or an empty string, then the user agent must ignore this element.
After following the definitions to the terms given in the
specification, the conformance requirement above can be
turned into one or more testable assertions (which are used to
derive test cases for the test suite).
An example of two testable assertion derived from the above conformance requirement:
-
Test that the user agent skips a content element with no src attribute and loads default start file. To pass, the user agent must use as start file index.htm at the root of the widget.
-
Test that the user agent skips a content element that points to a non-existing file. To pass, the user agent must use as start file index.htm.
And the corresponding test cases for the testable assertions take the following computable form (inteded for the user agent):
Each test case can be associated to a given
testable assertion; later on, when running the test suite and
finding test cases that fail, it allows identifying
the assertion behind it that has failed, and thus evaluate which
of the implementation, the test case, or the specification is
wrong.
To maintain the association between test
cases and test assertions, a simple XML file was created:
<testsuite for="http://www.w3.org/TR/widgets/">
<test id="b5"
for="ta-a1"
src="test-cases/ta-a1/000/b5.wgt">
Tests that a UA does not go searching in an
arbitrary folder ("abc123") for default start
files. To pass, the user agent must treat this
widget as an invalid widget.
</test>
<test ...> ... </test>
</testsuite>
The testsuite element serves as a wrapper for the test cases of the test suite. It also identifies which test suite was tested through a URI; set in the for attribute.
The test element, on the other had, describes a
single test case by:
-
Providing a
unique identifier for the test case; set in the id attribute.
-
Identifying the conformance requirement being tested; set in the for attribute.
-
Linking to the resource that represents the
test case; set in the src attribute.
-
And finally,
describing the expected outcome of the test; set as the textual
content of the element.
This XML file allows generating the final
round of packaging and information needed for the test suite:
-
its
content is integrated in the test suite description document [[WIDGETS-PC-TESTS]] with JavaScript to
attach test cases to the previously extracted test
assertions.
-
it
allows quick assessment of the coverage of the test suite by
finding which conformance requirements don’t have matching test
cases.
-
the
list of test cases can be used to create simple test
harnesses for widget runtime engines.
-
The
same list is used to generate an implementation report [[WIDGETS-PC-INTEROP]] comparing the results of running the test cases for various
run time engines.
The implementation reports also leverage the identifiers assigned to each test case to indicate if the implementation has passed or failed a test. In order to create the implementation reports, the Working Group created another simple XML format: each implementer is assigned an XML file, which in most cases they themselves maintain.
An example of the results format:
<results testsuite="http://dev.w3.org/2006/waf/widgets/test-suite/test-suite.xml"
id="Opera"
product="Opera widgets"
href="http://opera.com/browser/next">
<result for="b5" verdict="pass"/>
<result for="dn" verdict="fail">
Opera did not process the file because it did not
have a .wgt file extension.
</result>
</results>
The results element serves as a wrapper that describes what test suite was tested, and some basic details about the implementation by:
-
Identifying the test suite by its URI, set in the testsuite attribute.
-
Identifying the product in a human legible form; set in the product attribute.
-
Providing a hyperlink to where independent parties can either get more information about a product, or actually download the product so they can, where possible, verify the results independently.
The result element, on the other hand, describes individual results gained from testing including:
Tallying the results allowed the working group to easily visualize the data in the test suite for each product:
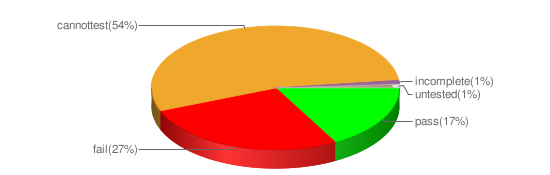
At at glance, it is possible to see for an implementation the number of tests cases passed, failed, and untested. Where the testing was being conducted independently (i.e., not by the implementer), it was also possible to visualize where it was not possible to run a test because, for example, there was no way to get at a result without having direct access to the source code of the product. And where the test ran, but it was not possible to determine if the test actually passed or failed, the verdict was labeled as incomplete.
Having the raw results data also allowed the working group to visualize at a glance how conformant each implementation is to the specification:
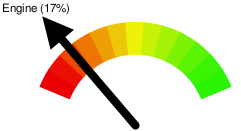
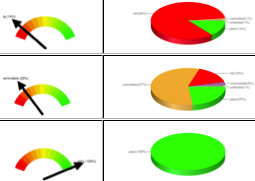
The above meter simply represents the number of tests passed by an implementation. However, the working groups found it particularly useful to be able to see all the meters and charts together:
Conclusions
While the method described in this document uses
three separate steps (marking
it up the specification, making the specification testable, and linking test assertions to test cases), these steps
don’t have to be applied sequentially, and in practice
work best as an iterative process.
Althought it has some limitations and shortcomings, this method has proved
effective for the [[WIDGETS]] specification, and is now being applied to the other Widgets
specifications developed by the Web Applications Working
Group.